英文原文:
Code Smells: If Statements
在这系列文章中迄今为止引发最多回复的是关于迭代的文章。今天我将探讨 if 语句(条件语句)。我不打算去遵循任何神圣的规则或其他东西——因为循环和 if 语句几乎是我们在许多编程语言中学习的第一个知识点。它们也是像 Java 这类编程语言的基本组成部分。但是,就是因为这些基本的构建块存在并不意味着它们每次就是我们的 goto 策略(看看我在这里做了什么?)。我们可以使用汇编程序编程,但是我们并没有这么做。我们可以用一把锤子完成房子周围的所有工作,但是我们也没有这么做。(好吧... 有点扯远了)
if 语句非常有用,而且往往是完成任务的正确工具,但他们也可能存在异味。记住,在这里使用“异味”,我的意思是“你应该仔细阅读代码,看看是否有一个更简单/更容易理解的方法”。我不是说“if 语句是邪恶的,永远不要使用它们”。
在前两篇文章中,我们已经看到了 validateQuery 这个函数中的异味。可能已经注意到我们忽略了构成方法主体的一系列 if。现在似乎是时候关注它们了。我们在前两篇博客中已经优化了这个方法,现在就(或多或少)从这个版本开始。我做了一些小改动,这样本文中对其重构会略为简单:
static ValidatedField validateQuery(final Class clazz, final Mapper mapper,
final String propertyPath, final boolean validateNames) {
final ValidatedField validatedField = new ValidatedField(propertyPath);
if (!propertyPath.startsWith("$")) {
final String[] pathElements = propertyPath.split(".");
final List<String> databasePathElements = new ArrayList<>(asList(pathElements));
if (clazz == null) {
return validatedField;
}
validatedField.mappedClass = mapper.getMappedClass(clazz);
for (int i = 0; ; ) {
final String fieldName = pathElements[i];
final boolean fieldIsArrayOperator = fieldName.equals("$");
Optional<MappedField> mf = validatedField.mappedClass.getMappedField(fieldName);
//translate from java field name to stored field name
if (!mf.isPresent() && !fieldIsArrayOperator) {
mf = validatedField.mappedClass.getMappedFieldByJavaField(fieldName);
if (validateNames && !mf.isPresent()) {
throw fieldNotFoundException(propertyPath, fieldName, validatedField.mappedClass);
}
if (mf.isPresent()) {
databasePathElements.set(i, mf.get().getNameToStore());
}
}
validatedField.mappedField = mf;
i++;
if (mf.isPresent() && mf.get().isMap()) {
//skip the map key validation, and move to the next fieldName
i++;
}
if (i >= pathElements.length) {
break;
}
if (!fieldIsArrayOperator) {
//catch people trying to search/update into @Reference/@Serialized fields
if (validateNames && (mf.get().isReference() || mf.get().hasAnnotation(Serialized.class))) {
throw cannotQueryPastFieldException(propertyPath, fieldName, validatedField);
}
if (!mf.isPresent() && validatedField.mappedClass.isInterface()) {
break;
} else if (!mf.isPresent()) {
throw fieldNotFoundException(propertyPath, validatedField);
}
//get the next MappedClass for the next field validation
MappedField mappedField = mf.get();
validatedField.mappedClass = mapper.getMappedClass((mappedField.isSingleValue()) ? mappedField.getType() : mappedField.getSubClass());
}
}
validatedField.databasePath = databasePathElements.stream().collect(joining("."));
}
return validatedField;
}不知道你是否还记得这个方法之所以引起我的注意,是因为里面有多次 isPresent 检查,其结果将 MappedField mf 封装在 Optional 当中。我希望 Optional 可以解决我的所有问题,但它没有。当然,问题不是 Optional 造成的 —— 现在我检查 isPresent() 的地方原来都是糟糕的空检查,因此我问自己,为什么我们需要进行这么多次空检查?易变性容易引起混乱,所以现在我们简化访问以减少其易变性。我们来仔细看看剩下的代码。
异味:if 语句
看看上面的代码,你可以看到 11 个不同的 if 语句,其中多数检查不只一个条件。两个包含 break,一个包含 return。代码中只有一个 else,它跟一个包含了 break 的 if 语句后面,这使它几乎毫无意义。在方法的结尾,你可能进入不止一个条件分支,很难明确为什么进入某个分支,以及它表示什么意思。
这个代码的问题在于它实际上做了两件事 —— 它(可能)验证了查询(基于 validateames 参数的值),还遍历了 String 属性路径并将其转换为一个域对象,MappedField 表示了这个路径末端的元素。我能理解为什么这两件事混在一起,因为它意味着它只需要迭代路径一遍,但是它 a) 需要一个标记来决定是否进行校验 b) 让它变很难搞明白哪些部分需要验证,哪些部分需要导航路径,以及哪些部分需要获取相关信息来获得恰当的 MappedFiled。最重要的是,某些条件也是用以控制循环条件的。
步骤1:把步入条件放在开始
这些 if 语句中,有一些是用来控制流程的 —— 如果可能的话,会从方法中返回。我想尽可能地把它们移到方法的前端,因此我的大脑会找到这些特殊条件,然后在方法剩下的部分忽略它们。
第一个很直接:
final ValidatedField validatedField = new ValidatedField(propertyPath);
if (!propertyPath.startsWith("$")) {
final String[] pathElements = propertyPath.split(".");
final List<String> databasePathElements = new ArrayList<>(asList(pathElements));
if (clazz == null) {
return validatedField;
}
//...我想把 clazz 上面的步入条件移到开始,但在第一个 if 之外。原因如下:1) 在这个检查之前的所有东西都不需要进行空检查,它不需要这些东西就能工作(不考虑 clazz 解析字符串的性能影响,当 clazz 是空的时候什么都不需要做) 2) 看起来正确的事情是检查参数值并在进入后面的逻辑之前尽可能快地退出。
您必须快速自我检查以确保这样的修改不会改变代码块中 method 的行为,因为有可能这个 method 会在空的 clazz 类下返回两个不同的值:一个值是以 $ 开头的属性路径,另一个则不是。如果纵观整个 method,我们会发现在两种情况下都返回新的 validatedField,所以将检查工作放到第一位是极好的:
final ValidatedField validatedField = new ValidatedField(propertyPath);
if (clazz == null) {
return validatedField;
}
if (!propertyPath.startsWith("$")) {
final String[] pathElements = propertyPath.split(".");
final List<String> databasePathElements = new ArrayList<>(asList(pathElements));在这里,我想做另一个与此无关的重构。 propertyPath 以美元符号 $ 开头是什么意思?为什么它如此重要?我们可以为此 if 语句添加一个注释来澄清其含义,但我通常偏好将这些条件包含在返回布尔值的 method 中,并给它一个有意义的名称:

if (!isOperator(propertyPath)) {
final String[] pathElements = propertyPath.split(".");
final List<String> databasePathElements = new ArrayList<>(asList(pathElements));
//... rest of the method here
}
private static boolean isOperator(String propertyPath) {
return propertyPath.startsWith("$");
}以美元符号 $ 开头的 MongoDB 路径通常是某种操作,而不是一个字段的路径,因此该方法只是忽略运算符而仅仅关心字段。实际上,如果我喜欢且觉得这样更易于理解,我可以通过将“not”推送到 method 中并将其称为 isFieldPath 来更好地将其反映在代码中。这完全取决于个人喜好。
步骤 2: 删除控制迭代的逻辑
在这段代码中滥用 for 循环让我感到苦恼:
for (int i = 0; ; ) {我想把它变成一个合适的 for 循环,又或者是 while 循环。在另一个版本中,我创建了自己的枚举来管理循环。从代码来看如何修复这个问题并不明显(在 IntelliJ IDEA 中也肯定没有魔法去重构)。 直接移动到这里:
for (int i = 0; i< pathElements.length; i++) {...但不会工作,因为我们在方法的内部管理 i 的增量。因此,我们必须确定管理循环的代码,并用一些在传统循环中工作的代码替换这些碎片。
i++;
if (mf.isPresent() && mf.get().isMap()) {
//skip the map key validation, and move to the next fieldName
i++;
}
if (i >= pathElements.length) {
break;
}代码正中的这个部分是操作索引并决定何时结束循环的。一旦我们确定了这一点,我们就可以决定删除或更改哪些部分。
此 i++ 可以用传统 for 循环中的 i++ 替换。但是如果我们去掉这一行并依赖循环增量,i 将会在循环结束时递增,而不是中途,所以我们需要考虑到这一点并做出适当的改动。
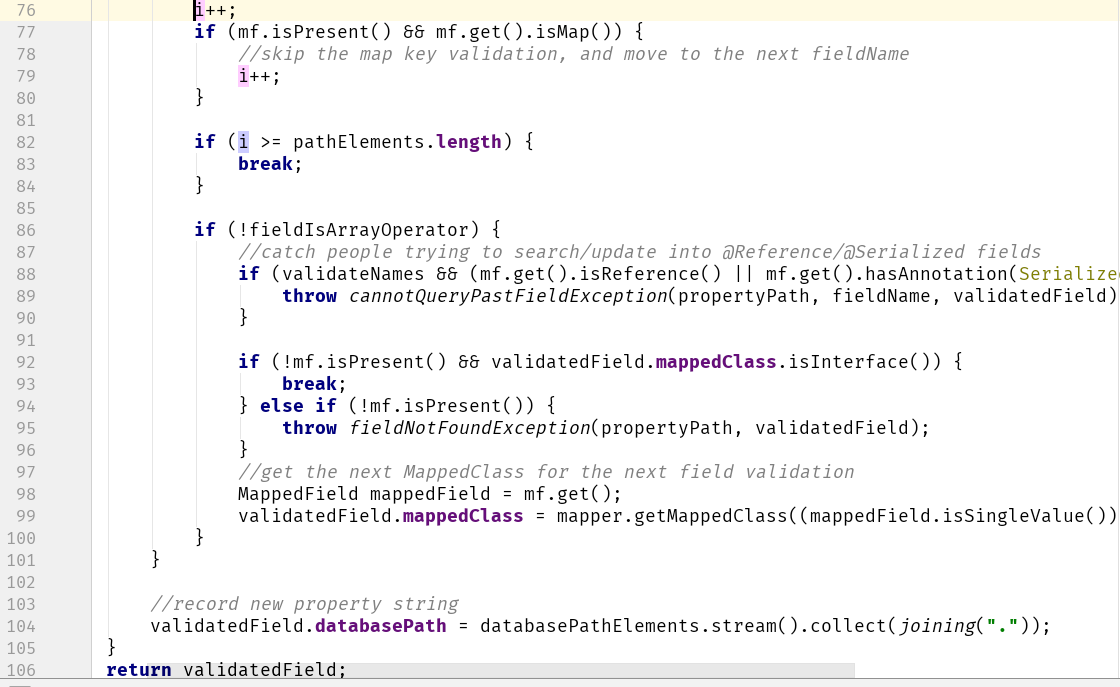
如果我们要删除此增量,则在第 76 行之后的任何地方之前使用 i 的值,需要使用 (i+1),因为这是之前的有效值。这种情况只存在于一个地方(第 82 行,见上),所以改起来很容易。
if ((i + 1) >= pathElements.length) {
break;
}有了这些改动,测试应该都能通过(幸运的是,它们确实如此)。
只有在当前元素之后有更多元素要处理时,中断语句之后的一切才会发生。从当前代码看这不是很明显,但如果我们翻转 if 语句...
...我们得到:
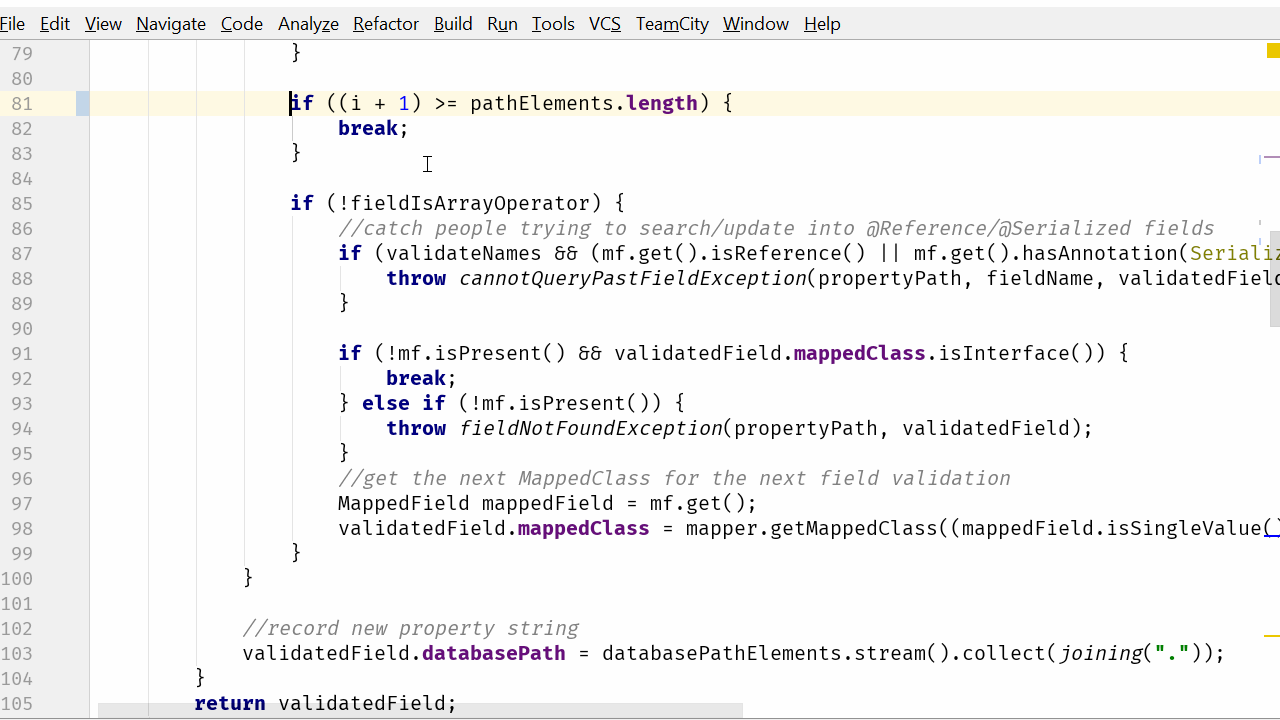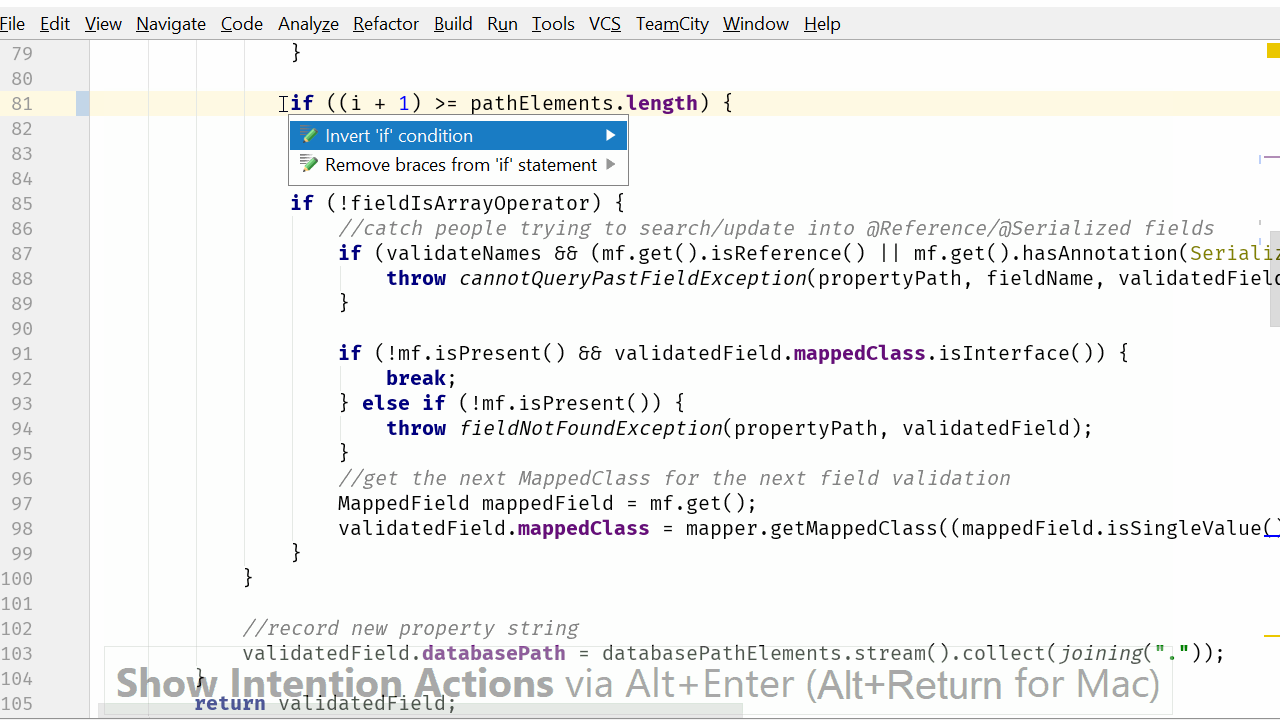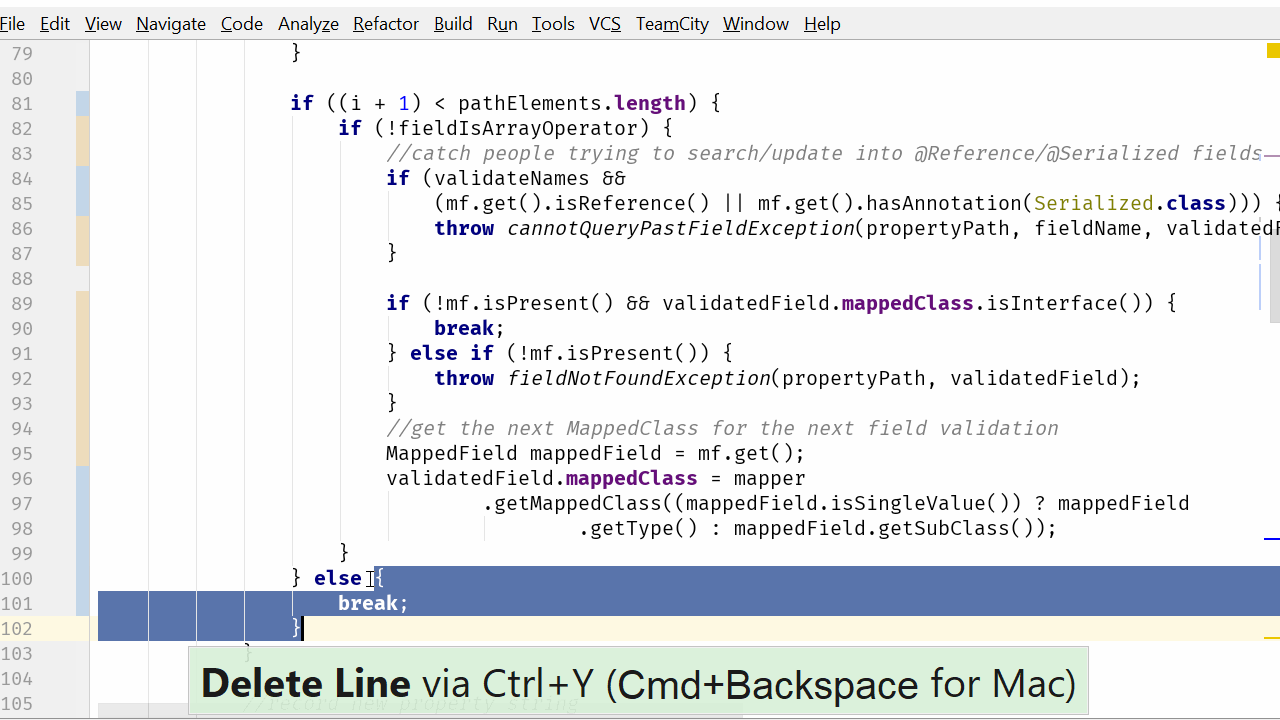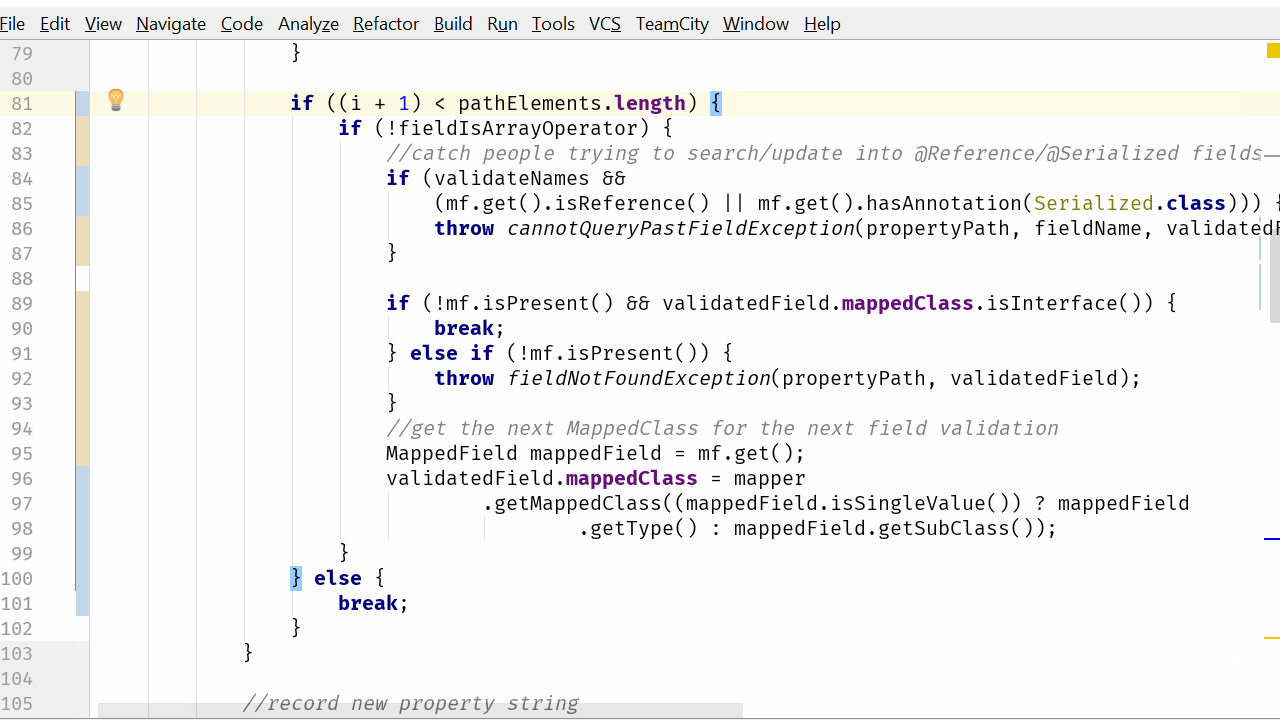
if ((i + 1) < pathElements.length) {
if (!fieldIsArrayOperator) {
//catch people trying to search/update into @Reference/@Serialized fields
if (validateNames &&
(mf.get().isReference() || mf.get().hasAnnotation(Serialized.class))) {
throw cannotQueryPastFieldException(propertyPath, fieldName, validatedField);
}
if (!mf.isPresent() && validatedField.mappedClass.isInterface()) {
break;
} else if (!mf.isPresent()) {
throw fieldNotFoundException(propertyPath, validatedField);
}
//get the next MappedClass for the next field validation
MappedField mappedField = mf.get();
validatedField.mappedClass = mapper.getMappedClass((mappedField.isSingleValue()) ? mappedField.getType() : mappedField.getSubClass());
}
} else {
break;
}现在我们使用一个适当的有保护条件的 for 循环,我们不再需要中断(特别是在方法的结尾处)。for 循环本身将确保不会越过数组的结尾。因此我们就可以完全删除这个 else 语句了。
步骤 3:提取方法以增强可读性
和以前一样,现在我对这些条件之一的状态感到相当满意,我将把条件提取到一个带有用名称的小方法中,这样我就能更好地理解我要检查的内容。
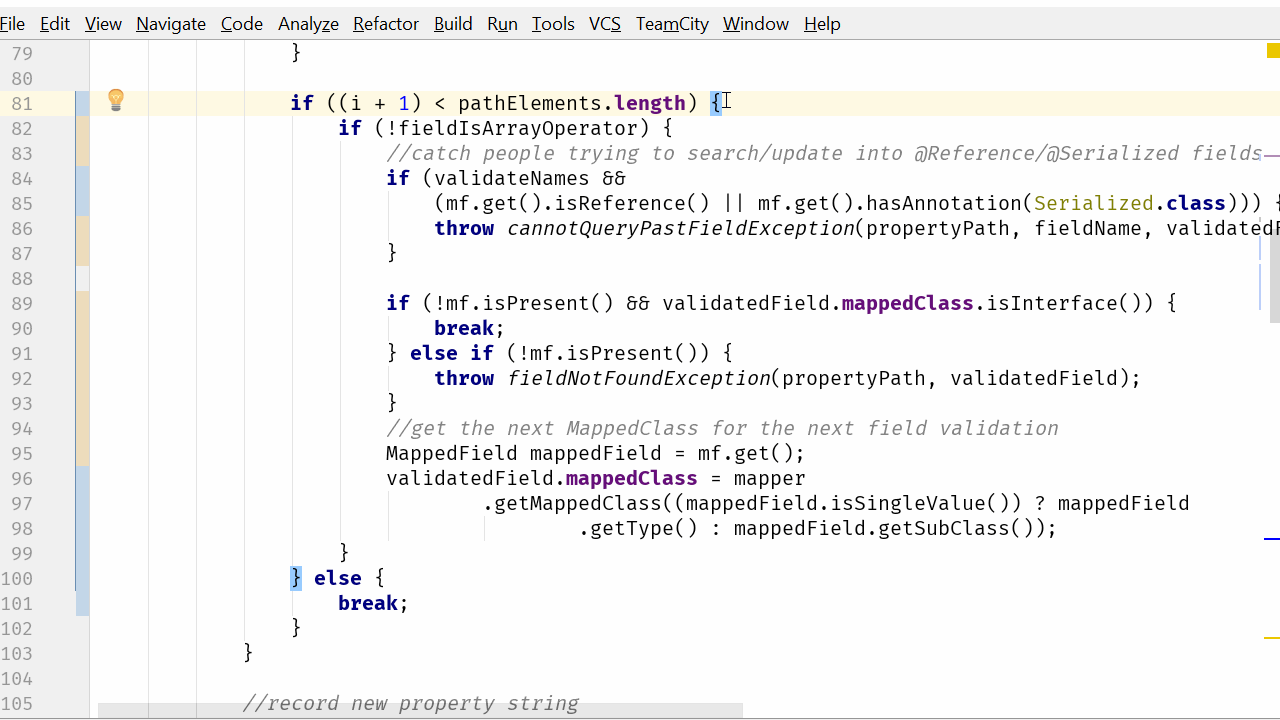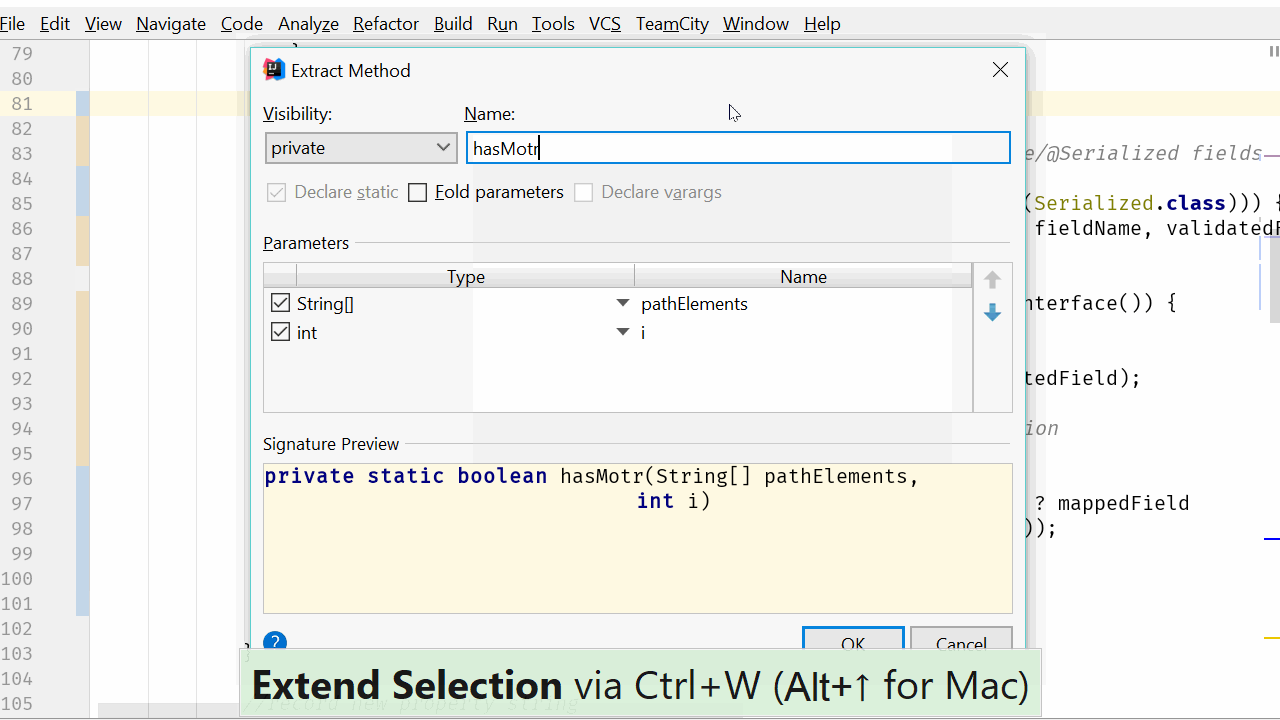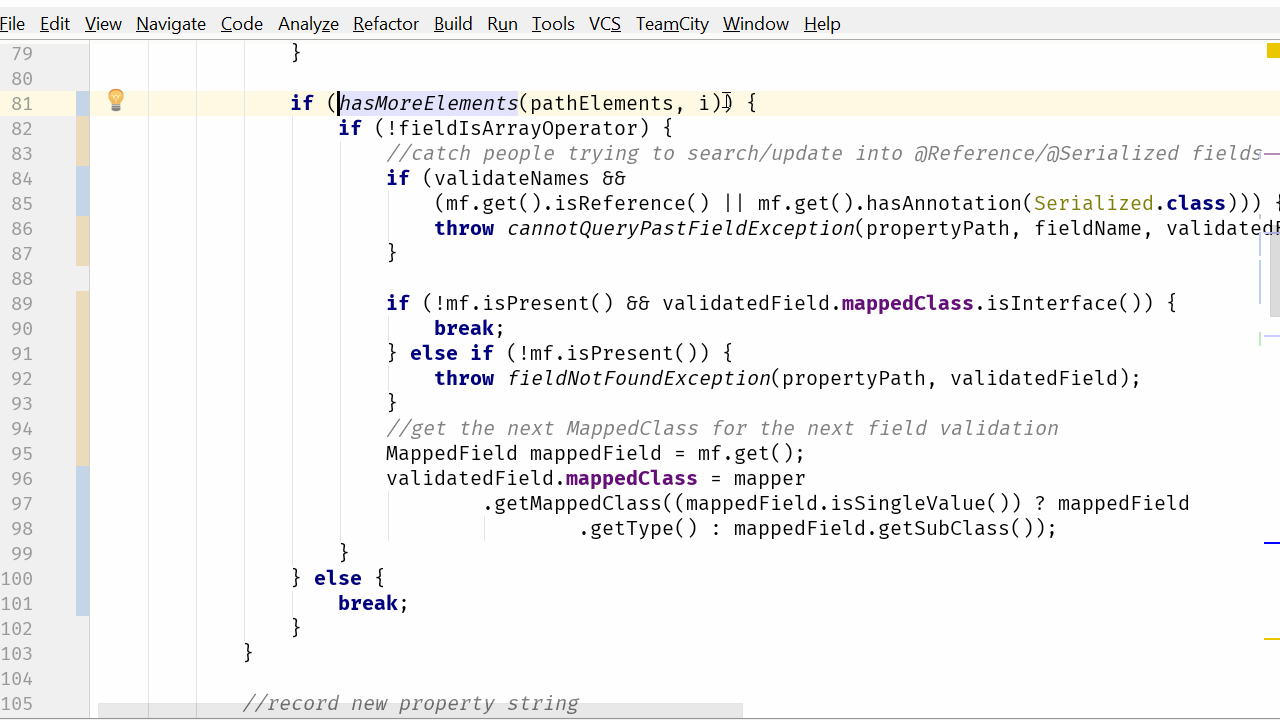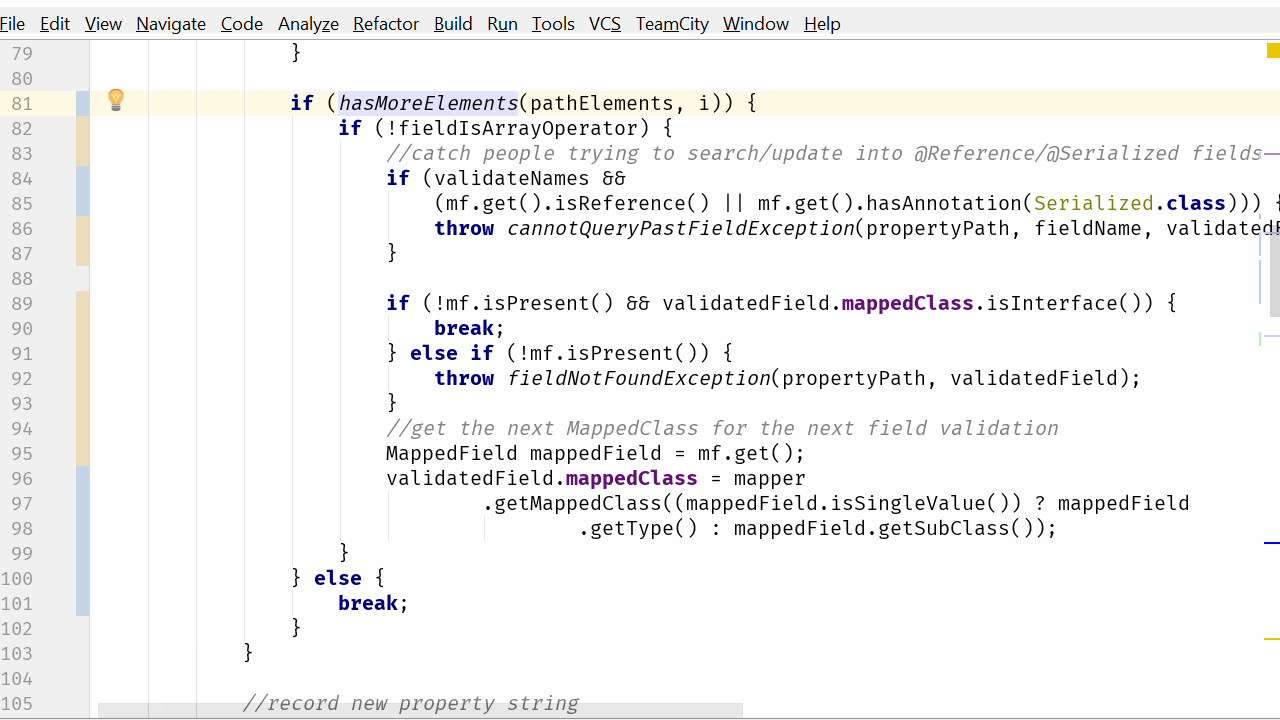
if (hasMoreElements(pathElements, i)) {
if (!fieldIsArrayOperator) {
// rest of the method....
}
private static boolean hasMoreElements(String[] pathElements, int index) {
return (index + 1) < pathElements.length;
}现在我们的代码更容易理解了。我们使用传统的 for 循环来遍历数组,所以我们把围绕索引递增和预防越过数组结尾的逻辑予以删除。这方面唯一复杂的是有意增加的增量以跳过特定值,但这一点更容易看到和理解。现在我们已经删除了所有其他索引管理。
步骤 4: 替换多个值的检查
几个 if 语句检查相同的条件,所以我想做的是看看是否可以分离这个条件的判断,只做一次,以简化逻辑。
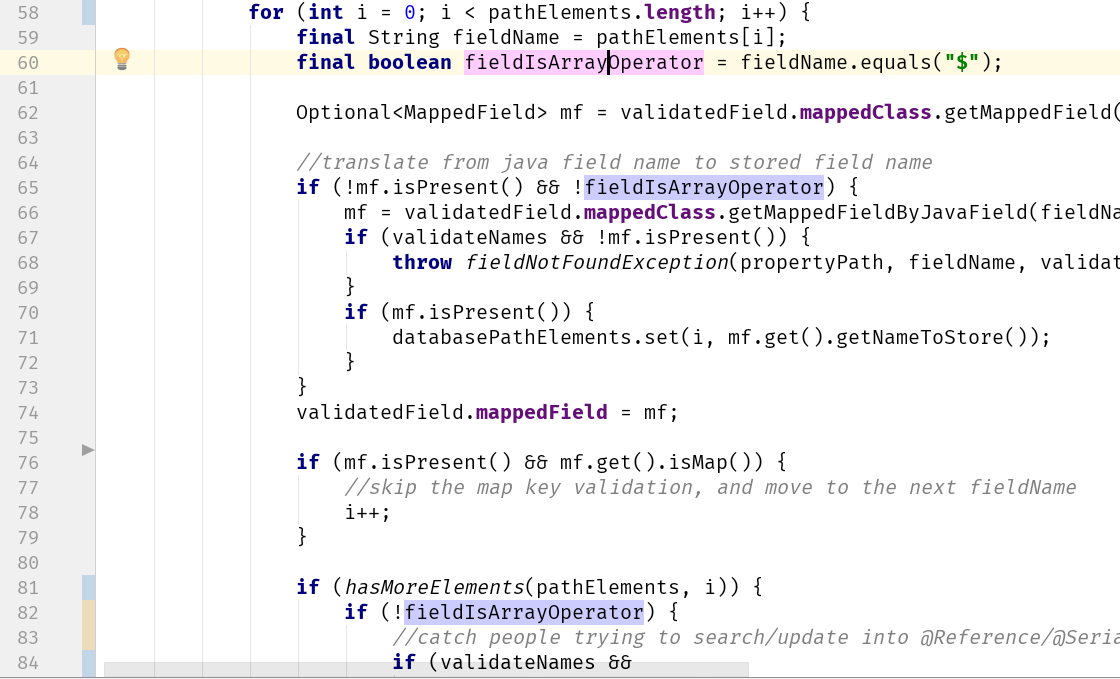
我们可以看到 fieldIsArrayOperator 被检查了两次,两次都判断它是否是一个数组运算符。因此,我的问题是:如果有的话,当它是一个数组运算符时,我们该做什么? 这里我们实际上或者需要深入分析代码,或者使用一些领域知识。
第 65 行:
if (!mf.isPresent() && !fieldIsArrayOperator) {
// ...do something
}如果它是一个数组运算符,不要运行此代码。
第 82 行
if (!fieldIsArrayOperator) {
//...do something
}如果它是一个数组运算符,不要运行此代码。
如果字段名称是数组运算符,则唯一执行的代码是:
Optional<MappedField> mf = validatedField.mappedClass.getMappedField(fieldName);
validatedField.mappedField = mf;
if (mf.isPresent() && mf.get().isMap()) {
//skip the map key validation, and move to the next fieldName
i++;
}通过研究、测试和/或领域知识,我们可以确定,当 fieldName 为“$”时,mf 总是为空,如果它是一个数组运算符,那么它不会是一个 Map。 因此,我可以断定:如果 fieldName 是数组运算符,任何代码都不会被执行。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接。
2KB翻译工作遵照
CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务





















