Python
英文原文:
The Future of Asynchronous IO in Python
免责声明:我是一个工程师,拥有10年以上的 WEB 后端开发经验,大部分职业生涯都在编写 Python代码。所以本文大部分文字描述可能跟软件开发的其他领域无关,同样的,也跟使用 JVM 或 CLR 的开发者无关,他们只是用不同的方式解决问题。
开发Web应用程序看起来与我们10年前做的有很大的不同。现在,我们用微服务建立的一切。它彻底改变了我们的应用程序的架构。
2014年,如果你还在构建完整巨大的 web 应用程序,你需要改变这一行为,否则很快会被解雇
虽然我们的应用程序的设计发生了很大变化,但是我们的工具没有。这里我要介绍未来我会如何编写微服务。但是,首先,让我们来看看我们有什么。
全局解释锁
对于声名狼籍的Python GIL,Python的支持者说的比较多的是其他的脚本语言也有(Ruby,Perl,Node.js,还有一些)。对于不好的语言解释器的设计,这是圣战的源头,但这对于web应用从来不是问题。我们总是以来许多进程共享一个数据库。
在微服务面前,全局解释锁更加不是问题了。在大多数情况下,单个微服务甚至比十年前的典型web应用还小。尽管很小,它每秒也可以处理大量的请求,大多数是因为它针对查询的类型,进行了高度的定制化和很好的调整。
而当构建的微服务需要等待其他服务回复的时间时,这开始成为一个问题。好戏由此开场。。。
“异步I / O,或非阻塞I/ O是输入/输出进程的一种形式,它允许其他进程继续在传输完成之前。”- 维基百科
任何异步库基本是从左侧到右侧的流程来调整代码的:
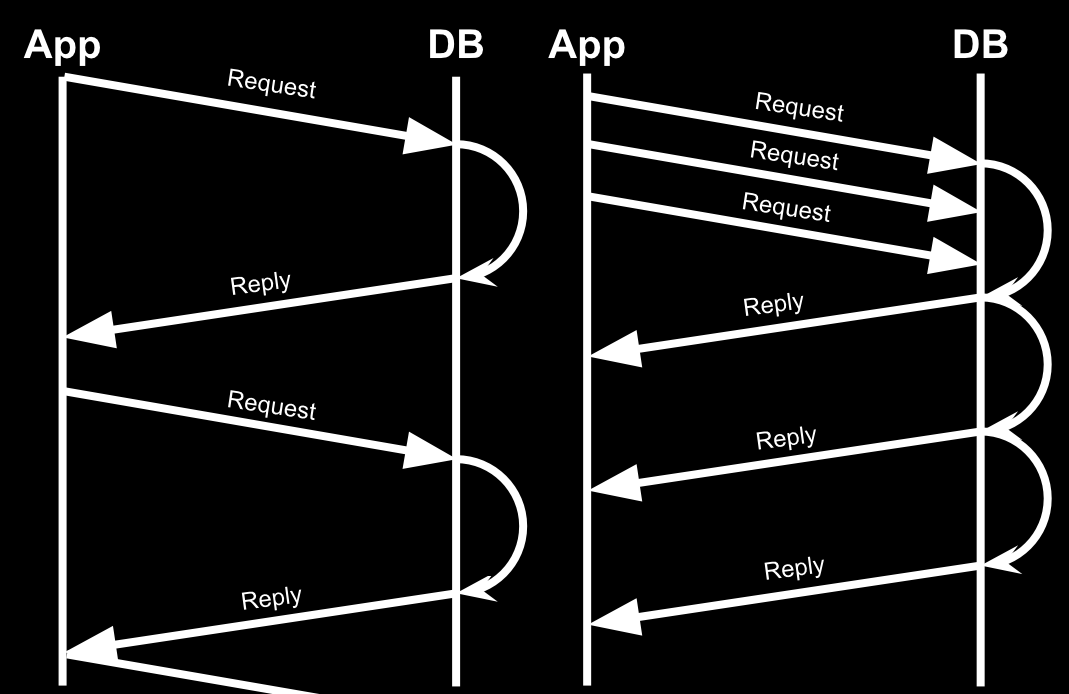
同步(左)与异步(右)请求进程对比图
Python的异步I/O支持是相当的好。有一堆库可以做这个工作(Twisted, Tornado, Gevent, Eventlet,这里仅列举几个)。每个库都支持很多协议。你可以使用MySQL, Mongo, PostgreSQL, Redis, Memcache, ElasticSearch...,几乎每个DB,和许多其他得服务。一些奇异的协议,像SSH或者Beanstalk只在几个库中支持。不过这些都不是问题,写另一个协议或从一个I/O框架移植到另一个也不是很难。
当然,每一个I/O库都支持客户端和服务端HTTP。想必,这就是为什么HTTP是最常见的用于微服务之间通信的协议。不过大多数框架也支持各种其他协议(msgpack-rpc, thrift, zeromq, ice,这里仅列举几个)。
有很多框架存在,彼此在不同协议的使用便捷性和其他种类的并发抽象上的有所不同。当然对不同协议的支持已经变得越来越流行。直到Twisted在2002年发布,这种状况才有所改变。是的,即使当python支持了yield和stackless及greenlets出现,便捷性确实大大增加了,但是这也仅仅是增加一点点的便捷性。真正的改变是在2002年。
但是有些事情是大多数Python框架的弱项。当你在一个线程中操控很多个客户端的请求时,你有可能把它们管道进单个连接中。也就是说,如果你在前端有三个GET请求,你可能向MySQL数据库发送三次请求,但不等待回复。一旦收到(数据库)的数据就尽快回复客户端。就像上面图中表示的,但是使用了单个DB连接。大多数python框架现在,在请求开始时从连接池中拉取一个连接,在请求结束时释放连接,这样高效的保证连接数目与同时请求数目相等。
对于多数数据库来说,成千上万个连接仍然是个问题。即使的典型的Sharding也无济于事,因为对每个shard来说也是相同数目的连接。很多用户采用了特殊的微服务(microservice)。这不仅仅是数据库的问题,许多微服务(microservice)也同样遇到这样问题。
幸好asyncio架构允许更容易的构建流水线(pipelining),所以越来越多的asyncio协议采用这种技术。不幸的是连接代价巨大的数据库(比如MySQL和PostgreSQL)使用了不支持(该技术)的C库,而且没有人有足够的重视来写一个更好的。
当前,许多工程团队围绕着发布-订阅来构建微服务(microservices)架构。比如,他们运用RabbitMQ或者其竞争者之一的产品将所有内容发布成消息(message)。他们相信这是简化他们的建构:
单总线(Single Bus),无须再考虑这个
能够无需等待回复即可发布消息。不需要任何异步库即可高效的获取异步I/O
当部分工程师们以为这就是答案的时候,我认为这不适合普遍的情况。
我认为将我的设计决策限制在使用特定插件及特定的消息调度算法不会解决我的所有网络问题。
另一个颇具魅力的微服务架构是Zeromq。如果你对它不熟悉,你应该尽快了解它。Zeromq只不过是巧合的使用MQ(消息队列)作为后缀,毕竟它不像 RabbitMQ,Kafka以及其他的那样拥有中心消息队列。它是以socket形式工作在steroids。也就是说,它看起来就像常规的socket,确实会自动发送消息(分割TCP数据流为帧),重新连接,点对点平衡加载等等。
在 Zeromq 世界里有三种方式供你的服务于其他连接:
发布-订阅,工作方式基本上和其他发布-订阅应用程序相同
请求-回复,基本与RPC工作方式相同
Push-Pull,请求却不需要回复,或者发布-订阅发送消息到单一接收端(基于轮叫)
Nanomsg 做到了更多事情,它不仅支持上面提到的所有方式,而且增加了更多的通信模式(单就nanomsg而言):
监督者-应答者(Surveyor-respondent),允许向多点发送请求而且接收来至所有的请求
总线(Bus),允许向任何点发送消息
更多的是:nanomsg的前景在于通信模式是插件式的,也就是说,在未来更多的通信模式会被增加到库中。
我相信更多的通信模式会出现,而使用发布-订阅或者HTTP难逃厄运
像nanomsg和zeromq作为脚本语言的优势是:它们在一个单独的线程中操控I/O。所以当你使用python做一些事情操控全局解释器锁(GIL)时,你的zeromq线程保持你的连接,清空消息缓冲器,接收和建立连接等等。
真实世界中的微服务
当聪明的黑客们创建了像 zeromq 、 nanomsg 和发布-订阅总线( publish-subscribe buses )这样优秀的项目的时候,实干的工程师们却仍然使用旧的技术干活。
到目前为止我还没有看到使用 zeromq 作为数据库存取通讯方式的数据库。嗯,现在是有很少一些使用了 zeromq 的开源服务。基本上所有现代的数据库在通讯方式的实现上目前分成了以下两个阵营:
创建并使用自身协议
使用 HTTP 协议
在这个方面数据库算是个比较突出的例子。另外的例子比如 Docker , Docker 使用了基于 unix sockets 的 HTTP 协议作为其通讯协议,然而,当她需要使用全双工流( full-duplex streams )来替代请求-回应( request-reply )模式的时候,就只能很不优雅地打破了其使用的协议的语义( protocol semantics )。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接。
2KB翻译工作遵照
CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务



















