JBoss Data Grid
英文原文:
JBoss Data Grid: Installation and Development
这篇博文将介绍一款来自Redhat的特别的data grid平台,也就是JBoss Data Grid (JDG). 首先说说如何获取和安装这个平台,然后演示利用HotRod协议如何开发和部署一个简单的远程客户端/服务端数据网格程序。这篇文章使用来自Redhat最新的JDG6.2.
安装概述
使用JDG之前,首先登陆 redhat 网站https://access.redhat.com/home 并在Downloads栏下载软件。我们在该栏(Downloads)点击连接下载JDG6.2.当然,为备将来之用,也可以下载quickstart和maven仓库的zip文件。简单地解压JDG服务器包到环境中合适的目录即可完成安装。

JDG 概述
在这一小节,简短地概述下JDG安装包的内容和最需要注意的用户配置选项。给用户提供了两种运行时选项(runtime option)运行JDG,一种是standlone模式,另一种是clustered模式.我们可以通过调用<JDG_HOME>/bin目录下的standalone或clustered的启动脚本来运行JDG.配置这两种模式,我们需要配置standalone.xml和cluster.xml文件。我们想要创建一个分布式缓存(distributed cache),它将运行在3节点的JDG集群上,所以我们需要使用clustered启动脚本。
为了启动和把新缓存实例添加到JDG,我们在上述配置文件的xml中修改infinispan子系统。同时也要注意standalone和clesterd配置文件上原则性的差异,那就是在clustered配置文件中含有JGroups子系统配置元素,它允许在配置缓存实例(configured cache instance)间的通信和消息可以在一个JDG集群中。
开发环境安装和配置
本节中,我们将会详细描述如何开发和配置一个简单的数据网格应用,它将被部署到一个由三个节点组成的JDG集群上去。我们将展示如何在JDG中配置和部署一个分布式缓存,以及如何开发一个HotRod Java客户端程序,用来新增、修改和展示分布式缓存中的元素。首先我们来讨论如何在一个3节点JDG集群中设置一个分布式缓存。在这个例子中,我们会在一台机器上运行我们的JDG集群,每个JDG实例运行在不同的端口上。
首先,我们将在我们的机器上为三个JDG实例创建三个目录(server1, server2, server3),并把JDG安装文件解压到每个目录中。
我们要配置集群中的每一个节点,这需要我们把<JDG_HOME>server1jboss-datagrid-6.2.0-serverstandaloneconfiguration目录中的clustered.xml配置文件拷贝出来并重新命名。我们需要把"server1", "server2"和"server3"三个JDG实例中的该配置文件分别命名为"clustered1.xml", "clustered2.xml"和"clustered3.xml"。我们将修改这三个配置文件中的infinispan子系统,用来创建一个新的分布式缓存。这里只展示如何修改"server1"节点的"clustered1.xml"配置文件。下面的缓存配置在3个节点上都适用。
为了创建一个名为"directory-dist-cache"的新的分布式缓存,我们修改了"clustered1.xml"文件的下列元素。
<subsystem xmlns="urn:infinispan:server:endpoint:6.0">
<hotrod-connector socket-binding="hotrod" cache-container="clusteredcache">
<topology-state-transfer lazy-retrieval="false" lock-timeout="1000" replication-timeout="5000"/>
</hotrod-connector>
.........
<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="clusteredcache">
<cache-container name="clusteredcache" default-cache="default" statistics="true">
<transport executor="infinispan-transport" lock-timeout="60000"/>
......
<distributed-cache name="directory-dist-cache" mode="SYNC" owners="2" remote- timeout="30000" start="EAGER">
<locking isolation="READ_COMMITTED" acquire-timeout="30000" striping="false"/>
<eviction strategy="LRU" max-entries="20" />
<transaction mode="NONE"/>
</distributed-cache>
..............
</cache-container>
</subsystem>
<socket-binding-group name="standard-sockets" default-interface="public" port-offset="${jboss.socket.binding.port-offset:0}">
......
<socket-binding name="hotrod" interface="management" port="11222"/>
......
/socket-binding-group>
</server>
根据上面的配置,我们将讨论关键的元素和属性.
在infinispan终端子系统,我们将配置hotrod客户端,连接JDG服务器实例的socket 11222端口.
容纳每个缓存实例的缓存容器,它的名字将会保存在名为"clusteredcache"的容器里.
我们已经配置infinispan的核心子系统为名为"clusteredcacahe"的默认缓存容器.凭借它,通过设置的缓存入口,也就是statistics="true",我们可以收集jmx的统计信息.
我们已经创建了一个新的分布式的名为"directory-dist-cache"的缓存,由此,每个缓存入口都将会有两份拷贝,存储在三个集群节点中的两个节点之中.
我们也制定了回收策略, 由此,当缓存中有超过20个入口的时候,将根据LRU算法将入口删除.
我们已经配置了节点"server2"和"server3", 并设置端口偏移分别为100和200,以便合理的设置socket绑定组元素.请查看下面的socket绑定.
为了在"server2"设置socket绑定元素的端口偏移为100,我们通过下面的入口来配置"clustered2.xml":
<socket-binding-group name="standard-sockets" default-interface="public" port-offset="${jboss.socket.binding.port-offset:100}">
......
<socket-binding name="hotrod" interface="management" port="11222"/>
......
/socket-binding-group>
为了在"server3"设置socket绑定元素的端口偏移为200,我们通过下面的入口来配置"clustered3.xml":
<socket-binding-group name="standard-sockets" default-interface="public" port-offset="${jboss.socket.binding.port-offset:200}">
......
<socket-binding name="hotrod" interface="management" port="11222"/>
......
/socket-binding-group>
在讨论Hotrod客户端的安装和配置以前,我们将启动每一个服务器实例,以保证我们新配置的JDG分布式缓存正确启动了. 其中,Hotrod客户端将用来与JDG分布式HotRod服务器进行交互.
开启三个Windows或Linux控制台,并执行下面的启动命令:
控制台1:
1) 进入目录<JDG_HOME>server1jboss-datagrid-6.2.0-server�in
2) 执行这个命令以启动我们的JDG分布式服务的第一个实例"server1": clustered -c=clustered1.xml -Djboss.node.name=server1
控制台2:
1) 进入目录<JDG_HOME>server2jboss-datagrid-6.2.0-server�in
2) 执行这个命令以启动我们的JDG分布式服务的第二个实例 "server2": clustered -c=clustered2.xml -Djboss.node.name=server2
控制台3:
1) 进入目录<JDG_HOME>server3jboss-datagrid-6.2.0-server�in
2) 执行这个命令以启动我们的JDG分布式服务的第三个实例 "server3": clustered -c=clustered3.xml -Djboss.node.name=server3
当三个JDG实例已经正确启动后,应该可以看到控制台窗口的输出信息.从信息里面,我们可以看到在JGroups中有3个JDG实例:

HotRod客户端开发设置
既然Hotrod服务器已经启动运行起来了,我们就需要开发一个Hotrod Java客户端,用来和集群化的服务器应用进行交互。开发环境由下列工具组成。
1) JDK Hotspot 1.7.0_45
2) IDE - Eclipse Kepler Build id: 20130919-0819
HotRod客户端程序是一个由两个Java类组成的简单应用。该程序允许用户从JDG服务器获取一个分布式缓存的使用说明,然后执行下列操作:
a) 添加一个新的cinema(电影院)对象。
b) 给每个cinema对象添加和删除电影。
c) 打印存储在分布式缓存上的所有电影院和电影。
相关源代码可以从https://github.com/davewinters/JDG上下载。这里我们可以使用maven来构建和执行我们的应用,修改maven的settings.xml配置文件来指向我们之前下载的maven存储库文件,然后修改maven的项目配置文件(pom.xml)来构建并运行客户端应用。
在本文中,我们将使用Eclipse IDE创建应用程序,并在命令行运行客户端程序.为了创建一个HotRod客户端程序,并运行示例程序,我们需要完成如下的步骤:
1) 在Eclipse中创建一个Java工程.
2) 创建一个名为uk.co.c2b2.jdg.hotrod的包, 并导入源代码--之前提到的,从Github下载的源代码.
3) 现在需要配置Eclipse中的build路径,以包含编译程序所需的合适的JDG客户端jar文件.工程的build路径也要包含所有的客户端jar文件.这些jar文件包含在JDG安装zip文件之中.例如,在我的机器上,这些jar文件所在目录为: <JDG_HOME>server1jboss-datagrid-6.2.0-serverclienthotrodjava
4. 设置好Eclipse的build路径后,编译程序源代码应该没有问题.
5. 我们将打开控制台窗口并执行下面的命令来运行Hotrod程序.注意,这里指定的路径可能会有差别,它依赖于JDG客户端jar文件的路径以及个人环境中的应用程序类文件所在路径:
java -classpath ".;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavacommons-pool-1.6-redhat-4.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavainfinispan-client-hotrod-6.0.1.Final-redhat-2.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavainfinispan-commons-6.0.1.Final-redhat-2.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavainfinispan-query-dsl-6.0.1.Final-redhat-2.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavainfinispan-remote-query-client-6.0.1.Final-redhat-2.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavajboss-logging-3.1.2.GA-redhat-1.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavajboss-marshalling-1.4.2.Final-redhat-2.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavajboss-marshalling-river-1.4.2.Final-redhat-2.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavaprotobuf-java-2.5.0.jar;C:UsersDavidInstallsjbossdatagrids62server1jboss-datagrid-6.2.0-serverclienthotrodjavaprotostream-1.0.0.CR1-redhat-1.jar" uk/co/c2b2/jdg/hotrod/CinemaDirectory
6. Hotrod客户端在运行时,提供了一些不同的选项给用户,以便于和分布式的缓存进行交互,正如我们在下面的控制台窗口所看到的那样.
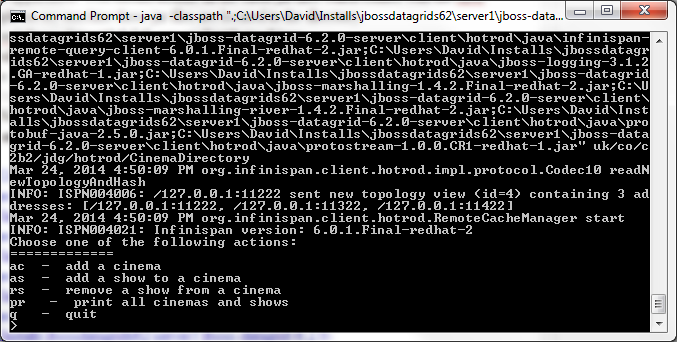
客户端应用程序主要API的细节
我们没有提供Hotrod应用程序代码的详细叙述,但我们将简要的描述主要API及其代码细节.
为了通过Hotrod协议与JDG集群上的分布式缓存进行交互,我们需要使用RemoteCacheManager对象,它将获取一个分布式缓存的远程引用.我们已经使用JDG实例的列表和每个实例的HotRod服务器端口,初始化了一个Properties对象.我们可以通过RemoteCache.put()方法来增加Cinema对象到分布式缓存.
private RemoteCacheManager cacheManager;
private RemoteCache<String, Object> cache;
.....
Properties properties = new Properties();
properties.setProperty(ConfigurationProperties.SERVER_LIST, "127.0.0.1:11222;127.0.0.1:11322;127.0.0.1:11422");
cacheManager = new RemoteCacheManager(properties);
cache = cacheManager.getCache("directory-dist-cache");
.....
cache.put(cinemaKey, cinemalist);
在下面的讨论中,我更深入的描述了如何安装JDG集群,以及,如何根据上面所谈到的,开发和运行JDG应用程序.获取更多细节请访问: http://www.redhat.com/products/jbossenterprisemiddleware/data-grid/.
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接。
2KB翻译工作遵照
CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务



















