英文原文:
A Cross-platform Parser of the Dynamic Disks Structure
序文
这篇文章对那些研讨硬盘驱动构造,开发那些用来更改磁盘构造的适用顺序,或关于那些在备份,数据恢复或信息提取方面需求处置触及到硬盘驱动构造问题的人很有协助。
起首,我们从根底Start研讨:甚么是静态磁盘,它和通俗磁盘的差别是甚么。别的,我们还会探求相干类型的静态卷的优缺陷。
接下来的章节会处置静态磁盘的外部构造:包含磁盘和卷怎么构成,它们之间怎么衔接,这些构造是存储在那里的,和怎么处置好它们。
基于对静态磁盘构造的了解,完成了相干的剖析器。第三部分引见剖析器。开发的这个剖析器是跨平台的。
静态磁盘:根底
我们先从术语Start:
磁盘-已衔接到系统的硬盘驱动器。每一个磁盘可以包括一个,多个或0个分区。
分区-硬盘驱动器单位,凡是为了实用性被系统说明为一个自力的全体。
卷- 一系列分区,凡是被系统说明为一个自力的逻辑磁盘。一个卷可以由一个或多个分区构成。
磁盘品种。静态磁盘与根本磁盘差别
磁盘可所以根本的或静态的。
根本磁盘有一个容易的逻辑构造:硬盘驱动器经过分区表可以划分为几个分区。每一个分区是一个逻辑磁盘,换句话说,一个卷老是由一个分区组成。这意味着一个卷只能被物理地定位在一个磁盘上。为了增加或减少卷的巨细,需求修改与这个卷相干的分区的巨细。
静态磁盘具有一个较为庞杂的逻辑构造:一个卷可以由位于一个或多个磁盘上的一个或多个分区组成。当要增加或减少卷的巨细时,可以经过改动与这个卷相干的分区的巨细完成,也能够经过增加新的分区或删除已有分区完成。
与根本卷比拟,静态卷有以下的特别用处(取决于卷的类型):
可以经过附加硬盘驱动器来增加卷的巨细;
经过多个硬盘驱动器的并行记载来进步功能。
多个磁盘进步牢靠性;一个磁盘的失败不会惹起数据丧失。
静态卷品种
让我们发明更多类型的静态卷及其特色。以下是静态卷的品种:
1.容易卷(*** volume)。它与在根本磁盘上的容易卷类似。它由一个辨别构成。它也能够包括多个分区,但这个卷的一切分区都位于统一个磁盘上。在牢靠性,过剩度或功能上与根本卷没有差别。容易卷在RAID阵列中没有类似物。
2.跨区卷(spanned volume)。它由位于分歧磁盘上的多个分区组成。与根本磁盘比拟,它可以创立大尺寸卷,将几个磁盘的空间组合起来。在牢靠性,过剩度或功能上与根本卷没有差别。跨区卷在RAID阵列中没有类似物。
3.带区卷(striped volume)。它与跨区卷类似;它们专一的差别是记载办法:数据被划分红块,并同时将块记入磁盘。换句话说,第一个块被记载到第一个磁盘,第二个块记入第二个磁盘,顺次类推。它的牢靠性较低,由于一个磁盘的失败会惹起一切数据的丧失。它没有过剩度。由于是并行操作,它的功能是相当高的。带区卷与RAID-0阵列类似。
4.镜像卷(Mirrored volume)。它由分歧磁盘上的两个分区构成。这些分区是它们之间的互相复成品,也就是说数据是反复的。它的牢靠性较高,由于一旦某一个磁盘失败了,第二个磁盘仍可以接纳数据。它的过剩度也很高:由于数据在两个分区中是反复的,可用空间只要总空间的50%。它的功能低于其他品种的卷。镜像卷与RAID-1阵列类似。
5.RAID-5。它由位于分歧磁盘上的3个或更多的分区构成。在卷上的操作是并行的,这对功能有必定的晋升。分区中的一个用来存储纠错码。它的牢靠性较高,由于一个磁盘的失败可以经过纠错码恢单数据。它的过剩度比镜像卷低,可用空间巨细取决于磁盘的数目。由于并行操作,它的功能是相当高的。RAID-5卷与RAID-5阵列类似。
静态磁盘外部
一切与静态磁盘相干的构造都保管在LDM数据库中。LDM数据库持有每一个硬盘驱动器的拷贝。为了找到这个数据库,我们必需要思索分区表的运用。
由于MBR,静态磁盘将只能有专一一个与全部磁盘类似巨细的分区。这个分区的类型必需是0х42,即逻辑磁盘分区。而且LDM数据库保管在硬盘驱动器的最初1兆(MB)的空间中。
起首要提一下,在LDM数据库中的一切数据都以高字节序(big-endian)格局保管,这是当运用LDM数据库时要采取ByteReverse函数的缘由。
我们起首看到的LDM构造是一个私有头(PRIVHEAD)。它的偏移量是0xC00,而不是参考中所说的0x200。
PRIVHEAD有以下的表现:
struct PrivHead
{
uint8_t magic[8];
uint32_t checksum;
uint16_t major;
uint16_t minor;
uint64_t timestamp;
uint64_t sequenceNumber;
uint64_t primaryPrivateHeaderLBA;
uint64_t secondaryPrivateHeaderLBA;
uint8_t diskId[64];
uint8_t hostId[64];
uint8_t diskGroupId[64];
uint8_t diskGroupName[31];
uint32_t bytesPerBlock;
uint32_t privateHeaderFlags;
uint16_t publicRegionSliceNumber;
uint16_t privateRegionSliceNumber;
uint64_t publicRegionStart;
uint64_t publicRegionSize;
uint64_t privateRegionStart;
uint64_t privateRegionSize;
uint64_t primaryTocLba;
uint64_t secondaryTocLba;
uint32_t numberOfConfigs;
uint32_t numberOfLogs;
uint64_t configSize;
uint64_t logSize;
uint8_t diskSignature[4];
Guid diskSetGuid;
Guid diskSetGuidDupicate;
};
我们可以看出,PRIVHEAD包括了关于数据库的整体信息。我们需求特殊存眷以下两个字段:
1 privateRegionStart - LDM数据库偏移(私有区域)。我们必需从这个偏移Start盘算LDM其它构造体的偏移
2 primaryTocLba -内容表(TOC)偏移与私有区域是相干的
uint64_t TocOffset(const PrivHead* privhead, PhysicalDisk& drive)
{
uint64_t privateRegion = ByteReverse(privhead->privateRegionStart);
uint64_t tocOffset = ByteReverse(privhead->primaryTocLba);
return (privateRegion + tocOffset) * drive.SectorSize();
}
TOCBLOCK 包括关于LDM特点的信息。它的构造体以下:
struct TocRegion
{
uint8_t name[8];
uint16_t flags;
uint64_t start;
uint64_t size;
uint16_t unk1;
uint16_t copyNumber;
uint8_t zeroes[4];
};
struct TocBlock
{
uint8_t magic[8];
uint32_t checksum;
uint64_t updateSequenceNumber;
uint8_t zeroes[16];
TocRegion config;
TocRegion log;
};
我们可以看到,TOCBLOCK包括两部分的描绘-config和log。第一部分包括我们需求的数据的部分。
uint64_t VmdbOffset(const PrivHead* privhead, const TocBlock* tocblock, PhysicalDisk& drive)
{
uint64_t privateRegion = ByteReverse(privhead->privateRegionStart);
uint64_t configOffset = ByteReverse(tocblock->config.start);
return (privateRegion + configOffset) * drive.SectorSize();
}
假如我们应用config部分(与私有区域相干的)提到的偏移跳转到下一个LDM构造体,会失掉VMDB。它是VBLK链表的头。
struct Vmdb
{
uint8_t magic[4];
uint32_t sequenceNumberOfLastVblk;
uint32_t sizeOfVblk;
uint32_t firstVblkOffset;
uint16_t updateStatus;
uint16_t major;
uint16_t minor;
uint8_t diskGroupName[31];
uint8_t diskGroupGuid[64];
uint64_t committedSequence;
uint64_t pendingSequence;
uint32_t numberofCommittedVolumeBlocks;
uint32_t numberOfCommittedComponentBlocks;
uint32_t numberOfCommittedPartitionBlocks;
uint32_t numberOfCommittedDiskBlocks;
uint32_t numberOfCommittedDiskAccessRecords;
uint32_t unused1;
uint32_t unused2;
uint32_t numberOfPendingVolumeBlocks;
uint32_t numberOfPendingComponentBlocks;
uint32_t numberOfPendingPartitionBlocks;
uint32_t numberOfPendingDiskBlocks;
uint32_t numberOfPendingDiskAccessRecords;
uint32_t unused3;
uint32_t unused4;
//uint8_t zeroes[16]; VSFW 4.0 adds this field upon installation, and removes it during unsinstall, it is unclear how to detect if this field will appear or not, other than checking 0xCD to see if it's in use.
uint64_t lastAccessTime;
};
我们关怀第一个元素的偏移,元素巨细和最初一个元素的编号。VBLK从4Start计数,这就是为何规则了第一个元素是512,巨细是128。VMDB运用VBLK编号的0到3。
uint64_t FirstVblkOffset(
const PrivHead* privhead, const TocBlock* tocblock, const Vmdb* vmdb, PhysicalDisk& drive)
{
return VmdbOffset(privhead, tocblock, drive) + ByteReverse(vmdb->firstVblkOffset);
}
VBLK是数据库的一个元素,它代表了一类工具(卷,组件,分区,磁盘,磁盘组)。为了更好的了解这个工具,让我们探求它们的构造。
1.一个容易的卷包括一个组件,一个或多个分区,每个分区指向统一个磁盘。

1. 跨区卷和带区卷由一个组件组成,一个或多个分区指向分歧的磁盘
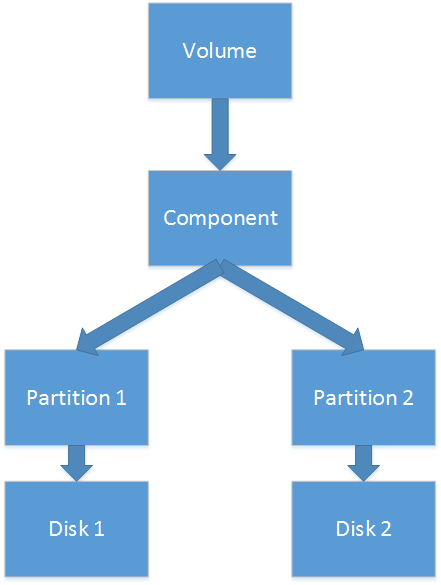
1. 镜像卷由两个组件组成,上面的数据是反复的。每个组件有一个分区,而且分区指向分歧的磁盘
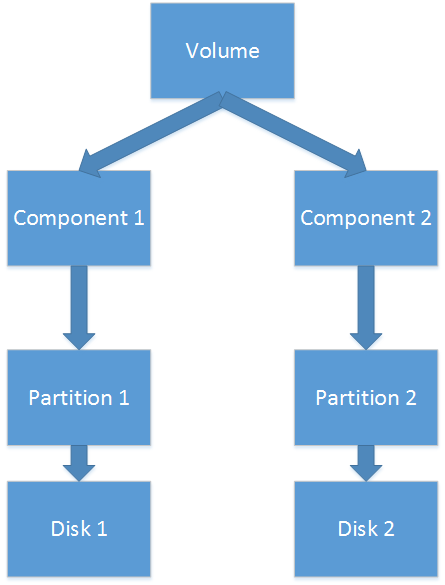
1. RAID-5的卷包括一个组件组成;组件有3个或更多的分区,它们辨别指向分歧的磁盘
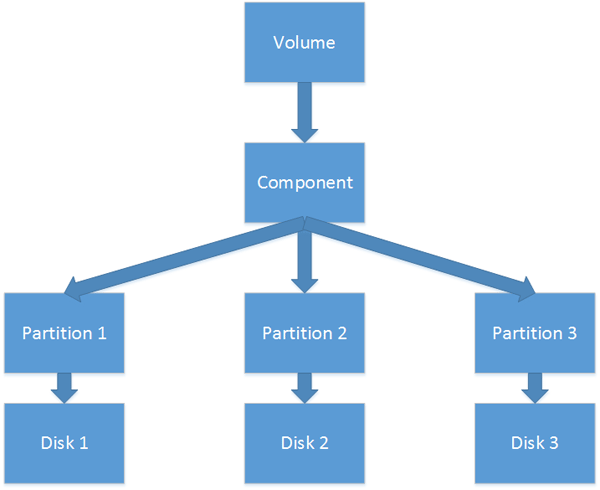
就我们所能看出的,实际上这类卷的构造可以支撑更多庞杂的卷类型。比方,镜像跨区卷应当有以下的外观。
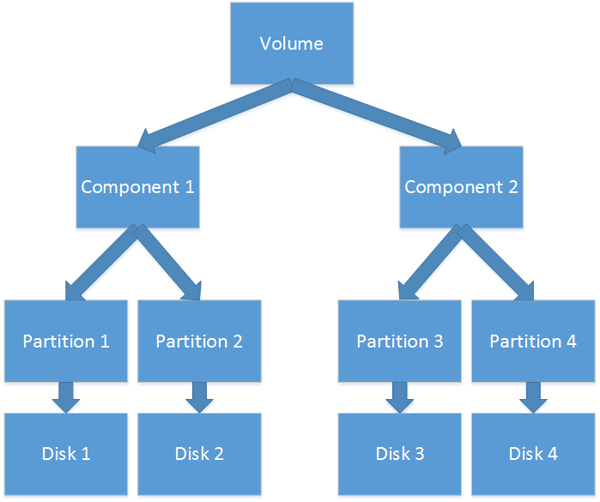
但在理论中,其实不支撑这这些类型的卷:不管是Windows系统的磁盘管理仍是第三方的磁盘Tools软件都不克不及创立如许的卷。假如你测验考试手动创立这些卷,Windows会回绝与其组盘任务,并标志它们为无效形态。
VBLK的内容依据它所代表的组件的类型分歧而分歧。但一切VBLK都有一个配合的规范头文件,用来断定VBLK的数目,组号,碎片的数目,和有单个碎片的文件数。
假如数据太大,没法存储在一个独自的VBLK中,其他的数据会被记载到另外一个VBLK构造中。这类构造用一个独自的组号衔接起来。
在一切类型的VBLK中,cell形态、flags、cell类型,和内容长度等信息存储在规范头前面。
struct VblkHeader
{
uint8_t magic[4];
uint32_t sequenceNumber;
uint32_t groupNumber;
uint16_t recordNumber;
uint16_t numberOfRecords;
};
struct ExtendedVblk
{
VblkHeader header;
uint16_t updateStatus;
uint8_t flags;
uint8_t type;
uint32_t length;
uint8_t otherData;
};
让我们讨论一下每品种型的VBLK的细胞构造。应当说,每一个工具都有独一的ID。LDM base 外部的衔接是运用工具的ID创立的。
VBLK外面非常多字段都是长度可变的。这类字段的第一个字节寄存数据的长度,然后依照数据规则的长度 存储。这类字段被用var的前缀标志出来。
1. 卷
struct VolumeVblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string type;
var_string disableDriveLetterAssignment;
int8_t state[14];
int8_t readPolicy;
var_uint64_t volumeNumber;
uint32_t flags;
var_uint64_t numberOfComponents;
uint64_t commitTransactionId;
uint64_t unknownTransactionId;
var_uint64_t size;
uint8_t zeroes[4];
uint8_t partitionType;
Guid guid;
var_uint64_t id1; //exists if vblk flags contain 0x08
var_uint64_t id2; //exists if vblk flags contain 0x20
var_uint64_t columnSizeLba; //exists if vblk flags contain 0x80
var_string mountHint; //exists if vblk flags contain 0x02
};
我们从卷取得以下信息:磁盘字符(假如曾经分派),卷巨细和运用的文件系统。
字段 type可能有两个值,gen和raid5。这个字段仅能通知我们它运用的能否是RAID-5的卷。
1.组件
struct ComponentVblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string state;
uint8_t layout;
uint32_t flags;
var_uint64_t numberOfPartitions;
uint64_t commitTransactionId;
uint64_t zero;
var_uint64_t volumeId;
var_uint64_t logsd;
var_uint64_t stripeSizeLba; //exists if vblk flags contain 0x10
var_uint64_t numberOfColumns; //exists if vblk flags contain 0x10
};
我们可以从组件取得以下信息:从partitionLayout字段(带状,延续的,RAID-5)取得卷类型,分区数 量,每一个组件属于的卷id。关于条带和raid卷我们还可以取得条带巨细。
1.分区
struct PartitionVblk //pseudocode
{
var_uint64_t objectId;
var_string name;
uint32_t flags;
uint64_t commitTransactionId;
uint64_t diskOffsetLba;
uint64_t partitionOffsetInColumnLba;
var_uint64_t sizeLba;
var_uint64_t componentId;
var_uint64_t diskId;
var_uint64_t columnIndex; //exists if vblk flags contain 0x08
var_uint64_t hiddenSectorsCount; //exists if vblk flags contain 0x02
};
我们能从分区中取得以下信息:在磁盘上的偏移(与公共区域相干),在卷中的偏移(假如卷是容易卷或是跨区卷),分区的巨细,组件ID和分区属于的磁盘ID。
1.磁盘
struct Disk1Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string guid;
var_string lastDeviceName;
uint32_t flags;
uint64_t commitTransactionId;
};
struct Disk2Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
Guid guid;
Guid diskSetGuid;
var_string lastDeviceName;
uint32_t flags;
uint64_t commitTransactionId;
};
从这个构造体我们可以取得磁盘的GUID,它也在PRIVHEAD构造体中存储。它可以用来联系关系磁盘,经过VBLK构造描绘为一个物理磁盘。
1.磁盘组
struct DiskGroup1Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string guid;
uint8_t zeroes[4];
uint64_t commitTransactionId;
var_uint64_t numberOfConfigs; //exists if vblk flags contain 0x08
var_uint64_t numberOfLogs; //exists if vblk flags contain 0x08
var_uint64_t minors; //exists if vblk flags contain 0x10
};
struct DiskGroup2Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
Guid guid;
Guid lastDiskSetGuid
uint8_t zeroes[4];
uint64_t commitTransactionId;
var_uint64_t numberOfConfigs; //exists if vblk flags contain 0x08
var_uint64_t numberOfLogs; //exists if vblk flags contain 0x08
var_uint64_t minors; //exists if vblk flags contain 0x10
};
这个构造体完好描绘了一组磁盘。我们可以从它取得组的称号和GUID。
剖析器描绘
如今让我们离开最有兴味的部分-剖析器的完成。静态磁盘剖析器的代码在这篇文章的附件中。
为了简化例子,我在完成过程当中作了一些假定。这就是为何在运用剖析器的过程当中我们需求思索以下方面:
1. 不论剖析器自身是一个跨平台的现实,它经过LDM的协助来处置静态磁盘
2. 今朝版本的剖析器仅经过MBR分区表处置静态磁盘。静态磁盘也能够运用GPT分区表。在这类状况下,我们需求查找LDM元数据部分,它寄存在数据库中。
3. 今朝版本的剖析器假定比来运用的LDM数据库寄存在第一个磁盘中,或许一切磁盘运用类似的LDM数据库。大部分情况,它不成能如许。像封闭或是破坏1个或多个静态磁盘的情况会惹起磁盘上的数据库变更。这就是为何一个完好的数据库(比方,一切的VBLK)需求在第一个磁盘上面操作,关于其他磁盘仅操作PRIVHEAD
4. 今朝版本的剖析器假定LDM数据库没有任何错误。LDM包括了分歧的信息用来维护数据库避免错误,可是这些信息不克不及够被剖析器运用。
5. 今朝版本的剖析假定VBLK的巨细,因而扇区可以寄存VBLK的整形数字。我曾碰到过VBLK的巨细仅为128字节,但这其实不会成为问题。
6. 今朝版本的剖析器假定一切的组件都在VBLK的构造体中。假如大的组件需求处置,我们需求将多个VBLK经过组编号衔接在一同。
7. 今朝版本的剖析器仅处置一种状况的磁盘和磁盘组VBLK构造体。我仅碰到过这类状况。假如需求,处置第二种状况的办法会被添加。
8. 今朝版本的剖析器采取小端形式架构。之前曾经提过一切数据在LDM数据库中是以大端形式存储的,这就是为何我在代码中添加ByteReverse函数,它用来处置这类数据格局问题。
9. 今朝版本的剖析器当盘算卷巨细时,运用512字节的扇区。假如LDM采取了这类优化,存储卷巨细在自力的字段,那末我将会以那种方法运用它。
本文中的一切译文仅用于进修和交换目标,转载请务必注明文章译者、出处、和本文链接。
2KB翻译任务按照
CC 协议,假如我们的任务有进犯到您的权益,请实时联络我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务



















