SysBench
英文原文:
ScaleArc: Benchmarking with sysbench
ScaleArc最近租用了Percona并对数据库流量管理产品执行各种测试。这篇文章是由Uday Sawant(ScaleArc)和我进行了基准测试的结果。你可以在这里下载PDF 报告。
这次基准的目标是识别ScaleArc软件自身可能的开销和使用缓存潜在的好处,对sysbench的主干版本进行基准测试。基于这个理由,我们使用一个非常小的数据集合,这样会更快得出测试结果,而我们都知道缓存在查询数据开销费用很大的情况下会发挥很大的作用。我们更倾向于在接下来的话题中介绍 real-world application的好处。如果你是在Silicon Valley领域的,请务必参加这前所未有的开源鉴赏日 ——我很乐意在这篇文章中把我的发现与你分享。这是免费的,但由于篇幅有限,所以你得先 注册。 我这一周也都会提供 Percona Live MySQL Conference and Expo 。
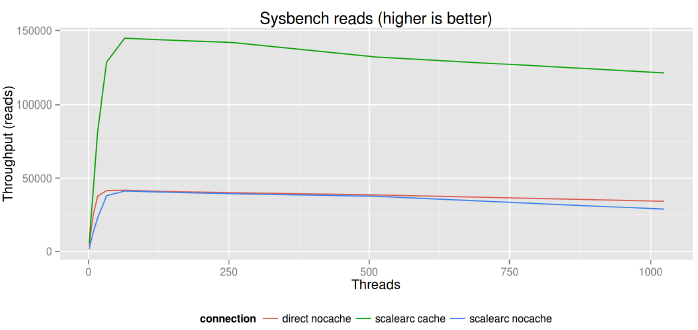
在这摘要图中我们可以看到,依据吞吐量(只读的基准,和读取最多的应用的有关),ScaleArc没有显著的开销,说明缓存发挥了潜在巨大的好处。
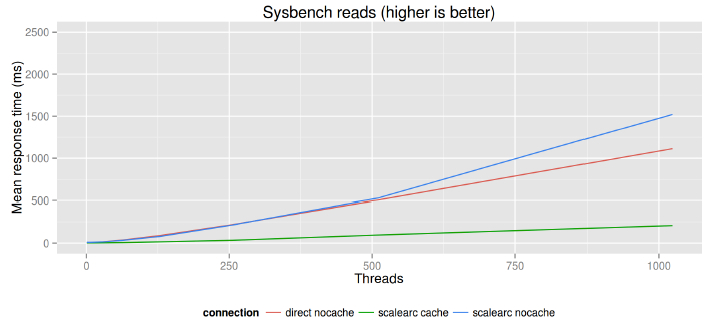
这个情况和响应时间非常类似。ScaleArc没有添加任何明显的开销,说明缓存在响应时间上同样发挥了巨大的好处。
如果是特定的工作负荷(这里是只读的sysbench),使用缓存意味着大致3倍增长的吞吐量以及缩减了80%的响应时间。
总而言之,ScaleArc是一个无论在性能方面还是功能方面很好的产品。我绝对会推荐它。
关于ScaleArc for MYSQL
ScaleArc for MySQL是一个软件应用,放置在应用程序和数据库之间,用于改善程序的可用性和性能。它不需要修改程序或者数据库,并提供:
基准设置
客户端电脑上运行像sysbench的基准测试软件作为基准。
CPU: 2 x Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz (6核, 关闭芯片多线程)
内存:64G
我们使用两个客户机。两个客户机的结果分别绘制,因此在数据库或者ScaleArc软件上有相同的工作负载是可见的。
数据库服务器
CPU: 2 x Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz (6核, 关闭芯片多线程)
内存:64G
运行MySQL Community Edition 5.6.15
MySQL配置
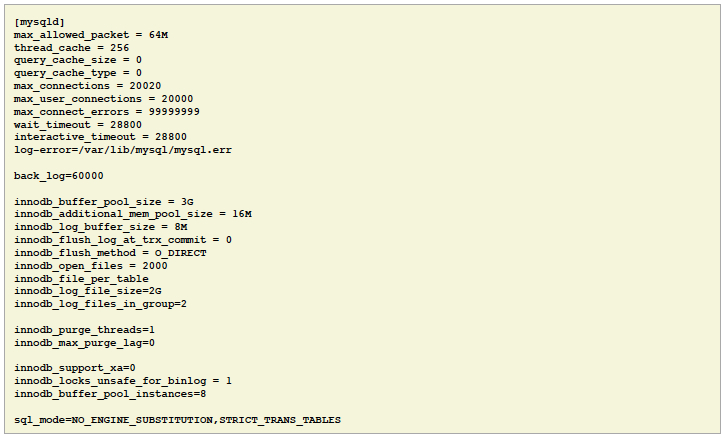
数据库的缓存池特意设置为较小,这样数据库将会很容易产生磁盘密集型的工作负载。
请注意下面的设置在生产环境是不推荐的
 我们用这些设置驱动数据库节点到峰值性能,避免任何在生产系统中可能的开销。在典型的生产设置中,这些都没有设置,binary logging是启用的,这将近一步减少ScaleArc软件的开销。
我们用这些设置驱动数据库节点到峰值性能,避免任何在生产系统中可能的开销。在典型的生产设置中,这些都没有设置,binary logging是启用的,这将近一步减少ScaleArc软件的开销。
ScaleArc软件应用
CPU: 1 x Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz (6核, 关闭芯片多线程)
内存:64G
运行ScaleArc for MySQL 3.0
网络
电脑之间通过10G网络连接。
[[需要为服务器增加ScaleArc的详细配置]]
测量
所有的的测量工作都在一个完全放置在内存中的非常小的数据库上进行。

在这些基准中,我们期望数据库和ScaleArc都是计算密集型的。如遇到磁盘密集型的工作负载,在这个基准测试中ScaleArc将会有更好的表现。假如查询是更昂贵的(他们不得不访问硬盘存储),开销的百分比会更小,查询缓存将更大。
我们测量三种不同的设置,都有只读和读写的用例。他们是:
直接连接到数据库
通过ScaleArc连接数据库,ScaleArc仅作为一个通过器(因此它对MySQL有线协议来说是一个负载均衡器,所有MySQL的机制仍然有效)。请注意,这个设置在实际的生产环境中是没有意义的。这个设置的目的是表明使用ScaleArc的潜在开销和暴露ScaleArc软件的潜在限制。[[你能说说在现实世界中会发生什么吗?例如:你将用ScaleArc均衡多台服务器的负载,这将提升性能并允许你汇集多台服务器的性能]]
通过ScaleArc连接数据库,允许ScaleArc缓存数据。ScaleArc是基于TTL的缓存,意味着一个读查询的结果将缓存在ScaleArc中。如果读查询在缓存到期前再次请求,这个查询将不再访问数据库服务器,而是直接读取ScaleArc中的缓存。一旦查询缓存的计时器到期,查询将再次访问数据库。当然,缓存仅适用于读操作,而不是在一个显式事务中(开启自动提交并且没有执行START TRANSACTION语句)。正因为如此,在只读用例中,在缓存基准期间我们使用–oltp-skip-trx参数。在这种情况的基准测试中,TTL设置为1小时,因为我们想让ScaleArc软件的缓存饱和。对一些应用来说1小时的TTL是不切实际的,但是对另一些应用来说有些查询甚至可以设置1天的TTL。[[你能添加ScaleArc的TTL从1秒到199天]]在这个用例中,我们想要测量缓存的性能,因此我们想在整个基准测试期间,查询被缓存,甚至系统在遇到很少的查询时,显示出潜在的收益。
基于TTL的缓存
注意到缓存的有效期是用TTL值控制是很重要的-其他的都是无效的,[[请看最后的注释]]因此在查询结果改变而缓存没有到期的时候,是有可能读取到旧数据的。对很多应用来说读取到独立的旧数据是没有问题的,对一个正规的异步的从服务器,当它的数据滞后于主服务器(它总是在有些地方滞后的)时,会发生读取旧数据的情况。否则,ScaleArc的缓存就非常类似于MySQL的查询缓存,MySQL的查询缓存不会遇到读取旧数据的问题,它有一个简单的失效机制(如果表被写入数据,属于给定表的缓存将被刷新)。当MySQL缓存正在刷新的时候,查询缓存的互斥将生效,甚至在那些正在读取的数据块上。因为互斥,内建的查询缓存很普遍的变成了性能瓶颈。ScaleArc的缓存是不会遇到这个问题的。
注意到ScaleArc在默认的情况下是不缓存任何数据是很重要的。另外,除了等待TTL过期之外,还有一些其他方法可能让缓存失效。
-
调用API(你能调用一个API使用查询模板规则清除缓存)
-
查询注释(你能在查询的前面放置/*wipe*/的注释,用于刷新缓存)
-
不缓存(你能发送注释/*nocache*/,对特定的查询不缓存其查询结果)
只读
Sysbench吞吐量

在少量线程区域(32个以内),由于经过ScaleArc我们发现TPS值有着显着的下降。这没有什么可大惊小怪的,其原因是网络损耗。因为scalearc是一个软件应用,它增加了数据库与应用程序之间的跳数,这样便产生了延迟。如果线程数比较多(32个以上),它的影响开始变得越来越小,但性能几乎相同,令人印象非常深刻。这意味着伴随着对这些机器的优化[[你可以添加“在那些跑最多应用的机器上”的理念]],ScaleArc只增加了非常小(几乎测不到)的开销。
Sysbench响应时间

这张图包含了前面基准测试的响应时间。在4096线程的时候,阅读真的很难,系统过载,响应时间超过了最大的吞吐量区。因为有多个数量等级,响应时间在这张图是不可读的。

接下来的这张图和上面的图是相同的,除了Y轴被限制在250ms,因此在上面可见的区域在这张图上就不可见了。我们看到的开销和吞吐量图几乎是一样的,这就意味着ScaleArc自身引入了不可估量的低延迟(这解释了用例中的差异,当并行性很低的时候)。通常连接数据库服务的应用程序都大量使用了多线程(在MySQL中,每个查询总是使用一个单独的线程,换句话说,就是在查询内部没有并行性)。当通过ScaleArc连接数据库的时候,在32个线程以上时,延迟会更低(基于CPU的数量,确切的临界点是有差异的)。其中的原因是ScaleArc本身使用一个事件循环来连接MySQL,因此在高并发时,能安排发送到MySQL的流量。
CPU利用率
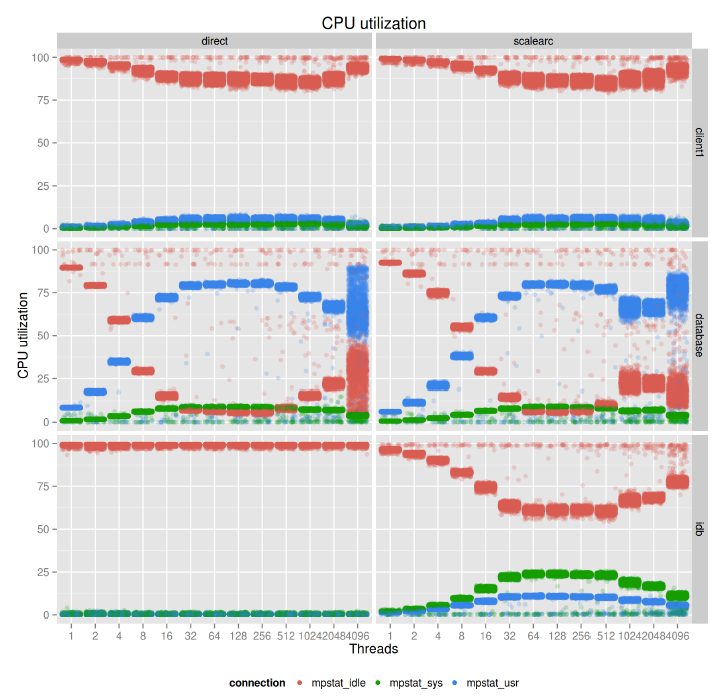
最后但并非最不重要的,此图包含了不同的设置的CPU利用率。左侧显示直接连接到数据库的CPU利用率,右侧显示通过ScaleArc连接的CPU利用率。在这两个用例中,数据库服务器的CPU都是瓶颈。可以看到客户端节点的CPU空闲状态超过75%(为了提高可得性仅绘制客户端1的数据,实际上客户端2的数据是相同的)。从32线程开始,在数据库服务器上蓝色条(user CPU利用率)相对于绿色条(sys CPU利用率)是比较高的。从64个线程开始,实际上CPU的空闲状态是0,直到系统过载。在右侧,我们可以看到,ScaleArc在这个负载的时候仍然有50%的CPU空闲,这就意味着实际上我们能通过ScaleArc在另外执行一组相同的基准测试,知道CPU完全被占用。在这儿,我们在讨论sysbench在3000 tps的情况。一个更有趣的事情要注意的是ibd比较高的系统时间。这也是因为ScaleArc连接到数据库的方式(见前面的图表)。
 这些现成来自于单一的客户端,这意味着在CPU利用率50%的时候ScaleArc能每秒解析84000条语句,这是令人影响深刻的。请注意,在这种情况下ScaleArc软件是按照工作负载类型调整的,这意味着我们有更多的查询处理线程。在遇到缓存的时候,我们有更多的缓存处理线程。
这些现成来自于单一的客户端,这意味着在CPU利用率50%的时候ScaleArc能每秒解析84000条语句,这是令人影响深刻的。请注意,在这种情况下ScaleArc软件是按照工作负载类型调整的,这意味着我们有更多的查询处理线程。在遇到缓存的时候,我们有更多的缓存处理线程。
缓存对只读工作负载的影响
Sysbench吞吐量
下面的图表将对比使用缓存和不使用缓存的情况
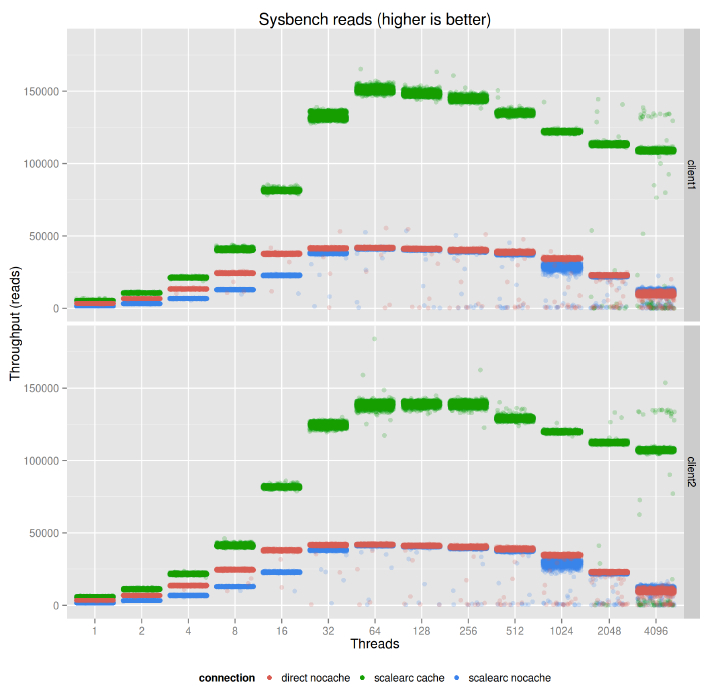
前面的TPS图包含了每秒的读取次数(因为我们使用了–oltp-skip-trx参数进行测量),因此在前面的设置中大致3000个事务产生了42000次读取(每个事务14次读取)。在图表的左侧,可以看见绿色的带缓存的吞吐量,在图表的右侧,可以看见红色(直接连接数据库)的和蓝色(通过ScaleArc连接数据库)的不使用缓存的吞吐量。可见缓存大幅的提升了速度,但是当ScaleArc超载(8192个客户端线程,每个客户端4096的线程)时,性能变得有些不一致,这是可以理解的,考虑到ScaleArc在很少的内核上是怎样运行的。在图表中,圆点是半透明的,这意味着色彩是明亮在具有多个样本的区域。即使在过载情况下,两个客户端的大多数样本仍然在每秒100K+读取次数的区域,这意味着即使在重负载时,性能下降的也非常优美。
Sysbench响应时间
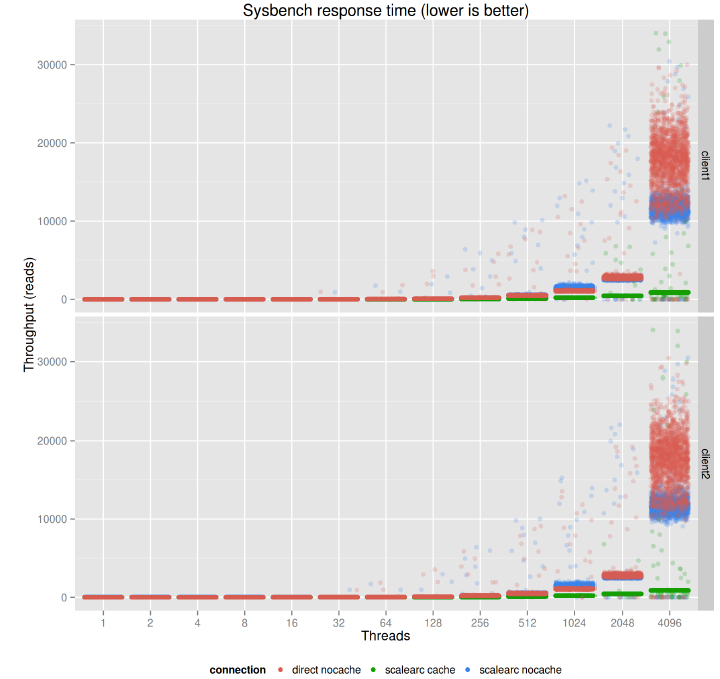
在工作负载无缓存的情况下,当系统过载时,响应时间非常大导致不可读。但是过载的响应时间是可见的,使用缓存不会使响应时间变得更差。
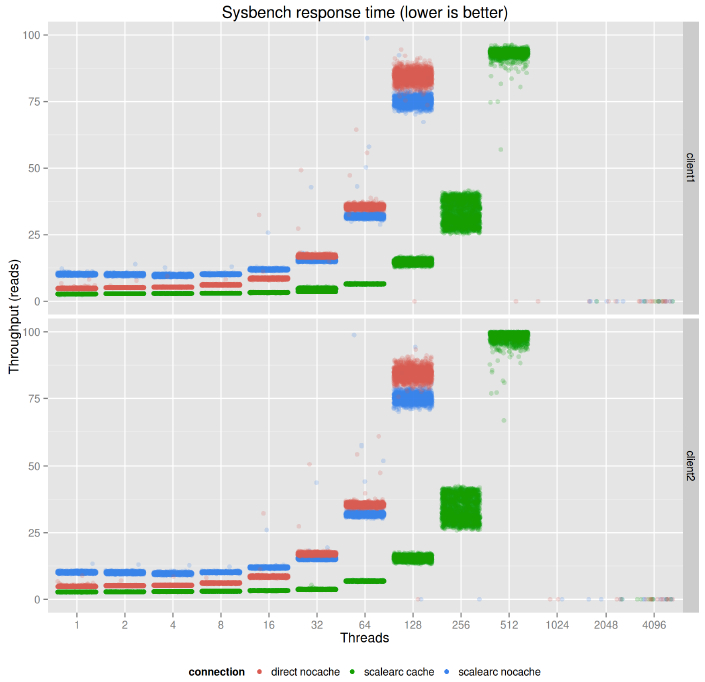
在工作负载无缓存的情况下,这张图表是前面图表的放大版。Y轴最大值为100ms。从这张图可见,缓存有助于提高响应时间,有更低的并发和更好的吞吐量。这是可以理解的,当缓存命中的时候,ScaleArc可以直接返回结果,客户端(在我们的例子中是指sysbench)不需要连接数据库,因此节省了来回和数据库处理的时间。另外值得一提的是数据来自于内存中[[我们不能明白接下来的部分]],这并不重要,如果我们命中了ScaleArc的数据库缓存.当ScaleArc使用缓存的时候,响应时间更低,因为避免了数据来回的时间和潜在的数据库工作(比如分析SQL语句)时间。这意味着缓存对数据的访问是有利的即使数据库本身有缓存池。当相对昂贵的查询如集合和查询在硬盘上时,缓存的帮助是最有效的。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接。
2KB翻译工作遵照
CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务






















