英文原文:
Use Subqueries to Count Distinct 50X Faster
注:这些技术是通用的,只不过我们选择使用Postgres的语法。使用独特的pgAdminIII生成解释图形。
很有用,但太慢
Count distinct是SQL分析时的祸根,因此它是我第一篇博客的不二选择。
首先:如果你有一个大的且能够容忍不精确的数据集,那像HyperLogLog这样的概率计数器应该是你最好的选择。(我们会在以后的博客中谈到HyperLogLog。)但对于需要快速、精准答案的查询,一些简单的子查询可以节省你很多时间。
让我们以我们一直使用的一个简单查询开始:哪个图表的用户访问量最大?
select
dashboards.name,
count(distinct time_on_site_logs.user_id)
from time_on_site_logs
join dashboards on time_on_site_logs.dashboard_id = dashboards.id
group by name
order by count desc
首先,我们假设user_id和dashboard_id上已经设置了索引,且有比图表和用户数多得多的日志条目。
一千万行数据时,查询需要48秒。要知道原因让我们看一下SQL解析:
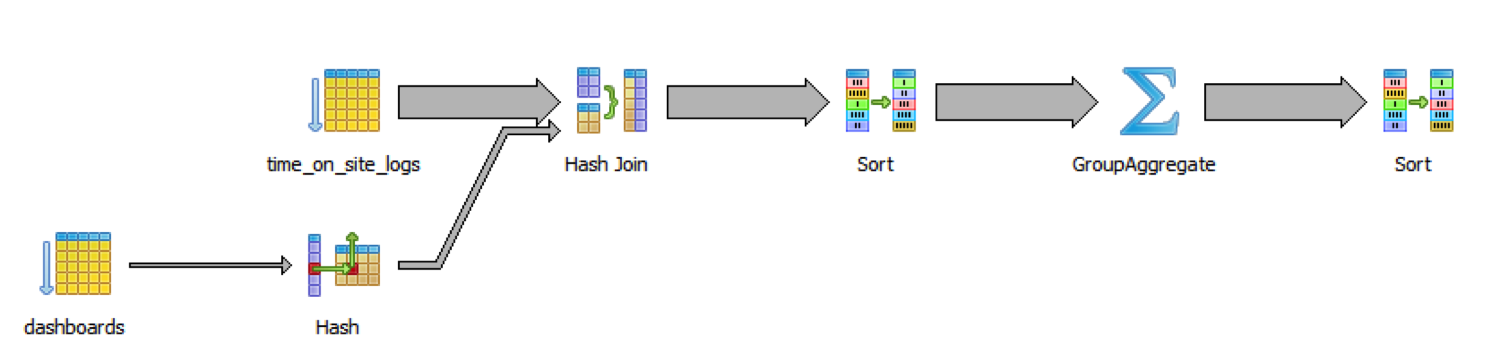
它慢是因为数据库遍历了所有日志以及所有的图表,然后join它们,再将它们排序,这些都在真正的group和分组和聚合工作之前。
先聚合,然后Join
group-聚合后的任何工作代价都要低,因为数据量会更小。group-聚合时我们不需使用dashboards.name,我们也可以先在数据库上做聚集,在join之前:
select
dashboards.name,
log_counts.ct
from dashboards
join (
select
dashboard_id,
count(distinct user_id) as ct
from time_on_site_logs
group by dashboard_id
) as log_counts
on log_counts.dashboard_id = dashboards.id
order by log_counts.ct desc
现在查询运行了20秒,提升了2.4倍。再次通过解析来看一下原因:

正如设计的,group-聚合在join之前。而且,额外的我们可以利用time_on_site_logs表里的索引。
首先,缩小数据集
我们可以做的更好。通过在整个日志表上group-聚合,我们处理了数据库中很多不必要的数据。Count distinct为每个group生成一个哈希——在本次环境中为每个dashboard_id——来跟踪哪些bucket中的哪些值已经检查过。
我们可以预先计算差异,而不是处理全部数据,这样只需要一个哈希集合。然后我们在此基础上做一个简单的聚集即可。
select
dashboards.name,
log_counts.ct
from dashboards
join (
select distinct_logs.dashboard_id,
count(1) as ct
from (
select distinct dashboard_id, user_id
from time_on_site_logs
) as distinct_logs
group by distinct_logs.dashboard_id
) as log_counts
on log_counts.dashboard_id = dashboards.id
order by log_counts.ct desc
我们采取内部的count-distinct-group,然后将数据拆成两部分分成两块。第一块计算distinct (dashboard_id, user_id) 。第二块在它们基础上运行一个简单group-count。跟上面一样,最后再join。

呵呵,大发现:这样只需要0.7秒!这比上面的查询快28倍,比原来的快了68倍。
通常,数据大小和类型很重要。上面的例子受益于基数中没多少换算。distinct (user_id, dashboard_id)相对于数据总量来说数量也很少。不同的对数越多,用来group和计数的唯一数据就越多——代价便会越来越大。
下一遇到长时间运行的count distinct时,尝试一些子查询来减负吧。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接。
2KB翻译工作遵照
CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务






















