Kafka
英文原文:
Kafka Architecture Design
我们为何要搭建该系统
Kafka是一个音讯系统,本来开辟自LinkedIn,用作LinkedIn的运动流(activity stream)和运营数据处置管道(pipeline)的根底。如今它已为多家分歧类型的公司 作为多品种型的数据管道(data pipeline)和音讯系统运用。
运动流数据是一切站点在对其网站运用状况做报表时要用到的数据中最惯例的部分。运动数据包含页面拜访量(page view)、被检查内容方面的信息和搜刮状况等外容。这类数据凡是的处置方法是先把各类运动以日记的方式写入某种文件,然后周期性地对这些文件实行统计剖析。运营数据指的是Server的功能数据(CPU、IO运用率、恳求工夫、办事日记等等数据)。运营数据的统计办法品种单一。
最近几年来,运动和运营数据处置曾经成了网站软件产物特征中一个相当主要的构成部分,这就需求一套略微愈加庞杂的根底设备对其供给支撑。
运动流和运营数据的若干用例
- "静态汇总(News feed)"功用。将你冤家的各类运动信息播送给你
- 相干性和排序。经过运用计数评级(count rating)、投票(votes)或许点击率( click-through)断定一组给定的条目中那一项是最相干的.
- 平安:网站需求屏障行动不真个收集爬虫(crawler),对API的运用实行速度限制,探测出分散渣滓信息的希图,并支持其它的行动探测和预防系统,以堵截网站的某些不正常运动。
- 运营监控:大大多数网站都需求某种方式的及时且因地制宜的方法,对网站运转效力实行监控并在有问题呈现的状况下能触发正告。
- 报表和批处置: 将数据装载到数据堆栈或许Hadoop系统中实行离线剖析,然后针对营业行动做出响应的报表,这类做法很广泛。
运动流数据的特色
这类由不成变(immutable)的运动数据构成的高吞吐量数据流代表了对盘算才能的一种真实的应战,因其数据量很轻易便可能会比网站中位于第二位的数据源的数据量大10到100倍。
传统的日记文件统计剖析对报表和批处置这类离线处置的状况来讲,是一种很不错且很有伸缩性的办法;可是这类办法关于及时处置来讲当时延太大,并且还具有较高的运营庞杂度。另外一方面,现有的音讯行列系统(messaging and queuing system)却很合适于在及时或近及时(near-real-time)的状况下运用,但它们对很长的未被处置的音讯行列的处置很不给力,常常其实不将数据耐久化作为重要的工作思索。如许就会形成一种状况,就是当把大量数据传送给Hadoop如许的离线系统后, 这些离线系统每一个小时或天天仅能处置掉部分源数据。Kafka的目标就是要成为一个行列平台,仅仅运用它就可以够既支撑离线又支撑在线运用这两种状况。
Kafka支撑十分通用的音讯语义(messaging semantics)。虽然我们这篇文章首要是想把它用于运动处置,但并没有任何限制性前提使得它仅仅实用于此目标。
安排
下面的表示图所示是在LinkedIn中安排后各系统构成的拓扑构造。
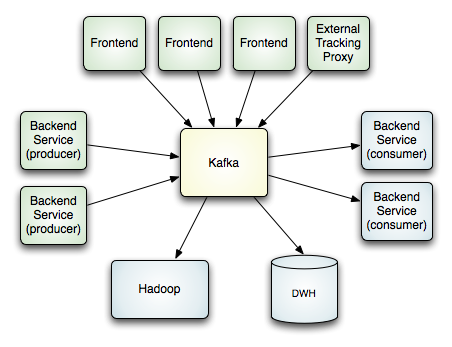
要留意的是,一个单个的Kafka集群系统用于处置来自各类分歧起源的一切运动数据。它同时为在线和离线的数据运用者供给了一个单个的数据管道,在线运动和异步处置之间构成了一个缓冲区层。我们还运用kafka,把一切数据复制(replicate)到别的一个分歧的数据中间去做离线处置。
我们其实不想让一个单个的Kafka集群系统逾越多个数据中间,而是想让Kafka支撑大多数据中间的数据流拓扑构造。这是经过在集群之间实行镜像或“同步”完成的。这个功用十分容易,镜像集群只是作为源集群的数据运用者的脚色运转。这意味着,一个单个的集群就可以够未来自多个数据中间的数据集中到一个地位。下面所示是可用于支撑批量装载(batch loads)的大多数据中间拓扑构造的一个例子:
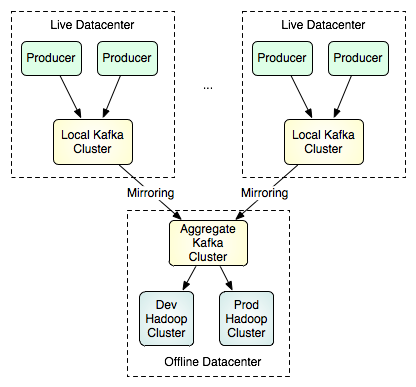
请留意,在图中上脸部分的两个集群之间不存在通讯衔接,二者可能巨细分歧,具有分歧数目的节点。下脸部分中的这个单个的集群可以镜像恣意数目的源集群。要了解镜像功用运用方面的更多细节,请拜访这里.
首要的设计元素
Kafka之所以和其它绝大大多数信息系统分歧,是由于下面这几个为数未几的比拟主要的设计决议计划:
- Kafka在设计之时为就将耐久化音讯作为凡是的运用状况实行了思索。
- 首要的设计束缚是吞吐量而不是功用。
- 有关哪些数据曾经被运用了的形态信息保管为数据运用者(consumer)的一部分,而不是保管在Server之上。
- Kafka是一种显式的散布式系统。它假定,数据生产者(producer)、代办署理(brokers)和数据运用者(consumer)疏散于多台机械之上。
以上这些设计决议计划将鄙人文中实行逐条胪陈。
根底常识
起首来看一些根本的术语和观点。
音讯指的是通讯的根本单元。由音讯生产者(producer)宣布关于某话题(topic)的音讯,这句话的意思是,音讯以一种物理方法被发送给了作为代办署理(broker)的Server(多是别的一台机械)。若干的音讯运用者(consumer)定阅(subscribe)某个话题,然后生产者所宣布的每条音讯城市被发送给一切的运用者。
Kafka是一个显式的散布式系统 —— 生产者、运用者和代办署理都可以运转在作为一个逻辑单元的、实行互相协作的集群中分歧的机械上。关于代办署理和生产者,这么做十分天然,但运用者却需求一些特别的支撑。每一个运用者过程都属于一个运用者小组(consumer group) 。精确地讲,每条音讯都只会发送给每一个运用者小组中的一个过程。因而,运用者小组使得很多过程或多台机械在逻辑上作为一个单个的运用者呈现。运用者小组这个观点十分弱小,可以用来支撑JMS中行列(queue)或许话题(topic)这两种语义。为了支撑行列 语义,我们可以将一切的运用者构成一个单个的运用者小组,在这类状况下,每条音讯城市发送给一个单个的运用者。为了支撑话题语义,可以将每一个运用者分到它本人的运用者小组中,随后一切的运用者将接纳到每条音讯。在我们的运用傍边,一种更常用的状况是,我们依照逻辑划分出多个运用者小组,每一个小组都是有作为一个逻辑全体的多台运用者盘算机构成的集群。在大数据的状况下,Kafka有个额定的长处,关于一个话题而言,不管有几多运用者定阅了它,一条条音讯都只会存储一次。
音讯耐久化(Message Persistence)及其缓存
不关键怕文件系统!
在抵消息实行存储弛缓存时,Kafka严重地依靠于文件系统。 大师广泛以为“磁盘很慢”,因此人们都对耐久化结(persistent structure)构可以供给说得过来的功能抱有疑心立场。实践上,同人们的希冀值比拟,磁盘可以说是既很慢又很快,这取决于磁盘的运用方法。设计的很好的磁盘构造常常可以和收集一样快。
磁盘功能方面最要害的一个现实是,在过来的十几年中,硬盘的吞吐量正在变得和磁盘寻道工夫严重纷歧致了。后果,在一个由6个7200rpm的SATA硬盘构成的RAID-5磁盘阵列上,线性写入(linear write)的速度约莫是300MB/秒,但随即写入却只要50k/秒,此中的差异靠近10000倍。线性读取和写入是一切运用形式中最具可估计性的一种方法,因此操纵系统采取预读(read-ahead)和后写(write-behind)技巧对磁盘读写实行探测并优化后后果也不错。预读就是提早将一个比拟大的磁盘块中内容读入内存,后写是将一些较小的逻辑写入操纵兼并起来构成比拟大的物理写入操纵。关于这个问题更深化的会商请参考这篇文章ACM Queue article;实践上他们发明,在某些状况下,次序磁盘拜访可以比随即内存拜访还要快!
为了抵消这类功能上的动摇,当代操纵系变得愈来愈努力地将主内存用作磁盘缓存。一切当代的操纵系统城市乐于将一切闲暇内存转做磁盘缓存,即时在需求收受接管这些内存的状况下会支出一些功能方面的价格。一切的磁盘读写操纵都需求颠末这个一致的缓存。想要舍弃这个特征都不太轻易,除非运用间接I/O。因而,关于一个过程而言,即便它在过程内的缓存中保管了一份数据,这份数据也可能在OS的页面缓存(pagecache)中有反复的一份,构造就成了一份数据保管了两次。
更进一步讲,我们是在JVM的根底之上开辟的系统,只需是了解过一些Java中内存运用办法的人都晓得这两点:
- Java工具的内存开支(overhead)十分大,常常是工具中存储的数据所占内存的两倍(或更糟)。
- Java中的内存渣滓收受接管会跟着堆内数据不时增加而变得愈来愈不明白,收受接管所破费的价格也会愈来愈大。
因为这些要素,运用文件系统并依靠于页面缓存要优于本人在内存中保护一个缓存或许甚么此外构造 —— 经过对一切闲暇内存主动具有拜访权,我们最少将可用的缓存巨细翻了一倍,然后经过保管紧缩后的字节构造而非单个工具,缓存可用巨细接着可能又翻了一倍。这么做下来,在GC功能不受丧失的状况下,我们可在一台具有32G内存的机械上取得高达28到30G的缓存。并且,这类缓存即便在办事重启以后会依然坚持有效,而不象过程内缓存,过程重启后还需求在内存中实行缓存重建(10G的缓存重建工夫可能需求10分钟),不然就需求以一个全空的缓存开端运转(这么做它的初始功能会十分蹩脚)。这还大大简化了代码,由于对缓存和文件系统之间的一致性实行保护的一切逻辑如今都是在OS中完成的,这事OS做起来要比我们在过程中做那种一次性的缓存愈加高效,精确性也更高。假如你运用磁盘的方法更偏向于线性读取操纵,那末跟着每次磁盘读取操纵,预读就可以十分高效运用随后准能用得着的数据填充缓存。
这就让人遐想到一个十分容易的设计计划:不是要在内存中保管尽量多的数据并在需求时将这些数据刷新(flush)到文件系统,而是我们要做完整相反的工作。一切数据都要立刻写入文件系统中耐久化的日记中但不实行刷新数据的任何挪用。实践中这么做意味着,数据被传输到OS内核的页面缓存中了,OS随后会将这些数据刷新到磁盘的。另外我们添加了一条基于设置装备摆设的刷新战略,答应用户对把数据刷新到物理磁盘的频率实行把持(每当接纳到N条音讯或许每过M秒),从而可认为系统硬件解体时“处于风险当中”的数据在量上加个上限。
这类以页面缓存为中间的设计作风在一篇解说Varnish的设计思惟的文章中有具体的描绘(文风略带有助于身心安康的傲气)。
本文中的一切译文仅用于进修和交换目标,转载请务必注明文章译者、出处、和本文链接。
2KB翻译任务按照
CC 协定,假如我们的任务有进犯到您的权益,请实时联络我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务




















{kind=link}