Hadoop
英文原文:
Apache Hadoop: Best Practices and Anti-Patterns
Apache Hadoop是一个用来构建大规模共享存储和计算设施的软件。Hadoop集群已经应用在多种研究和开发项目中,并且,Yahoo!, EBay, Facebook, LinkedIn, Twitter等公司,越来越多的的把它应用在生产环境中。 这些已有的经验是技术和投入的结晶,在许多情况下至关重要。因此,适当的使用Hadoop集群可以保证我们的投入能够获得最佳回报。
这篇博文简单总结了一些Hadoop应用的最佳实践。实际上,类似于设计模式,我们引进一个网格模式的的概念,来提供一个通用且可复用的针对运行在网格上的应用的解决方案。
这篇博文列举了表现良好的应用的特点并且提供了正确使用Hadoop框架的各种特性和功能的指导。这些特点很大程度上这由其本身特点而定,阅读这篇文档的一个好方法是从本质上理解应用,这些最佳实践在Hadoop的多租户环境下卓有成效,而且不会与框架本身的大多数原则和限制产生矛盾。
博文还强调了一些Hadoop应用的反模式。
概述
Hadoop上的数据处理应用一般使用Map-Reduce模型。
一个Map-Reduce作业通常会把输入的数据集拆分成许多独立的数据段,按照完全并行的方式一个map任务处理一段。框架把map的输出排序,然后作为reduce的输入。通常输入和输出都储存在文件系统。框架负责调度、监控任务的执行以及重启失败的任务。
Map-Reduce应用可以指定输入输出的位置,并提供了map与reduce功能的实现,体现在Hadoop中是Mapper 和Reducer.这些只是作业配置的一部分参数。Hadoop客户端提交作业(jar或者其他可执行的程序)和配置给JobTracker,而JobTracker负责把程序和配置分发到各个slave,调度和监控任务的执行,并返回状态信息给客户端。
Map/Reduce框架的处理是基于<key, value>这样的键值对,也就是说,框架吧输入数据视作一系列<key, value>键值对集合,然后产出另一些键值对作为输出。
这是 Map-Reduce应用的典型数据流
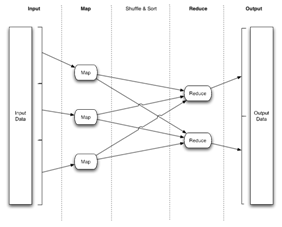
绝大多数在网格上运行的Map-Reduce应用都不会直接实现较低层次的Map-Reduce接口,而是借助于较高抽象层次的语言,例如Pig。
Oozie 是一个非常好的网格上的工作流管理和调度方案。Oozie 支持多种应用接口 (Hadoop Map-Reduce, Pig, Hadoop Streaming, Hadoop Pipes, 等等.) 并且支持基于时间或数据可用性的调度。
网格模式
这一部分是关于网格上运行的Map-Reduce应用的最佳实践
输入
Hadoop Map-Reduce 为处理海量数据而设计。maps过程以一种高度并行的方式来处理数据, 通常一个map至少处理一个HDFS block,一般是128M。
- 默认情况下,每个map最多处理一个HDFS 文件。 这意味着假如应用需要处理大量的文件,最好一个map能够处理多个。可以通过一种特定的输入格式来达成这个目的,就是MultiFileInputFormat。即使对于那些只处理很少小文件的应用,每个map处理多个文件的效率也更高。
- 假如应用需要处理的数据量非常大,即使文件尺寸很大,每个map处理128M以上的数据也会更有效率。
网格模式: 合并小文件以减少map数量,在处理大数据集的时候用比较大的HDFS 块大小。
Maps
maps的数量通常取决于输入大小, 也即输入文件的block数。 因此,假如你的输入数据有10TB,而block大小为128M,则需要82,000个map。
因为启动任务也需要时间,所以在一个较大的作业中,最好每个map任务的执行时间不要少于1分钟。
就像在上面“输入”部分所解释的,对于那种有大量小文件输入的的作业来说,一个map处理多个文件会更有效率。
如果应用处理的输入文件尺寸较大,每个map处理一个完整的HDFS block,数据段大一点更有效率。举个例子,让每个map处理更多数据,方法之一是让输入文件有更大的HDFS block尺寸,例如512M或者更多。
一个极端的例子是Map-Reduce开发团队用了大约66000个map来做PetaSort,也即66000个map要处理1PB数据,平均每个map 12.5G。
原则是大量运行时间很短的map会有损生产力。
网格模式:除非应用的map过程是CPU密集型,否则一个应用不应该有60000-70000个map。
当在map处理的block比较大的时候,确保有足够的内存作为排序缓冲区是非常重要的,这可以加速map端的排序过程。假如大多数的map输出都能在排序缓冲区中处理的话应用的性能会有极大的提升。这需要运行map过程的JVM具有更大的堆。记住反序列化输入的内存操作不同于磁盘操作;例如,Pig应用中的某些class将硬盘上的数据载入内存之后占用的空间会是其本来尺寸的3、4倍。在这种情况下,应用需要更大的JVM堆来让map的输入和输出数据能够保留在内存中。
网格模式:确保map的大小,使得所有的map输出可以在排序缓冲区中通过一次排序来完成操作。
合适的map数量有以下好处:
- 减少了调度的负担;更少的map意味着任务调度更简单,集群中可用的空闲槽更多。
- 有足够的内存将map输出容纳在排序缓存中,这使map端更有效率;
- 减少了需要shuffle map输出的寻址次数,每个map产生的输出可用于每一个reduce,因此寻址数就是map个数乘以reduce个数;
- 每个shuffled的片段更大,这减少了建立连接的相对开销,所谓相对开销是指相对于在网络中传输数据的过程。
- 这使reduce端合并map输出的过程更高效,因为合并的次数更少,因为需要合并的文件段更少了。
上述指南需要注意,一个map处理太多的数据不利于失败转移,因为单个map失败可能会造成应用的延迟。
Combiner
适当的使用Combiner可以优化map端的聚合。Combiner最主要的好处在于减少了shuffle过程从map端到reduce端的传输数据量。
Shuffle
适当的使用Combiner可以优化map端的聚合。Combiner最主要的好处在于减少了shuffle过程从map端到reduce端的传输数据量。
Combiner 也有一个性能损失点,因为它需要一次额外的对于map输出的序列化/反序列化过程。不能通过聚合将map端的输出减少到20-30%的话就不适用combiner。可以用 combiner input/output records counters(译者注:这是一个hadoop mapreduce 的counter名称,所以采用了原名未翻译)来衡量Combiner的效率。
网格模式:Combiners可以减少shuffle阶段的网络流量。但是,要保证Combiner 的聚合是确实有效的。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接。
2KB翻译工作遵照
CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务



















