盘算机根底
英文原文:
Memory part 2: CPU caches
[编者案:这是Ulrich Drepper写“顺序员都该晓得存储器”的第二部。那些没有读过第一部 的读者可能盼望从这一部Start。这本誊写的十分好,而且感激Ulrich受权我们出书。
一点阐明:册本出书时可能会有一些印刷错误,假如你发明,而且想让它在后续的出书中更正,请将看法发邮件到lwn@lwn.net ,我们必定会更正,并反应给Ulrich的文档正本,此外读者就不会遭到这些困扰。]
如今的CPU比25年前要精细很多了。在阿谁年月,CPU的频率与内存总线的频率根本在统一层面上。内存的拜访速度仅比存放器慢那末一点点。可是,这一场面在上世纪90年月被打破了。CPU的频率大大晋升,但内存总线的频率与内存芯片的功能却没有失掉成比例的晋升。并非由于造不出更快的内存,只是由于太贵了。内存假如要到达今朝CPU那样的速度,那末它的造价生怕要贵上好几个数目级。
假如有两个选项让你选择,一个是速度十分快、但容量很小的内存,一个是速度还算快、但容量非常多的内存,假如你的任务集比较大,超越了前一种状况,那末人们老是会选择第二个选项。缘由在于辅存(通常是磁盘)的速度。因为任务集超越主存,那末必需用辅存来保管交流出去的那部分数据,而辅存的速度常常要比主存慢上好几个数目级。
幸亏这问题也其实不全然长短甲即乙的选择。在设置装备摆设大量DRAM的同时,我们还可以设置装备摆设少数SRAM。将地址空间的某个部分划给SRAM,剩下的部分划给DRAM。大部分情况,SRAM可以看成扩大的存放器来运用。
上面的做法看起来仿佛可以,但实践上其实不可行。起首,将SRAM内存映照到过程的虚拟地址空间就是个十分庞杂的任务,并且,在这类做法中,每一个过程都需求管理这个SRAM区内存的分派。每一个过程可能有巨细完整分歧的SRAM区,而构成顺序的每一个模块也需求讨取属于本身的SRAM,更引入了额定的同步需求。简而言之,疾速内存带来的益处完整被额定的管理开支给抵消了。
因而,SRAM是作为CPU主动运用和管理的一个资本,而不是由OS或者用户管理的。在这类形式下,SRAM用来复制保管(或者叫缓存)主内存中有可能行将被CPU运用的数据。这意味着,在较短工夫内,CPU很有可能反复运转某一段代码,或者反复运用某部分数据。从代码上看,这意味着CPU履行了一个轮回,所以类似的代码一次又一次地履行(空间部分性的绝佳例子)。数据拜访也绝对局限在一个小的区间内。即便顺序运用的物理内存不是相连的,在短时间内顺序依然很有可能运用异样的数据(工夫部分性)。这个在代码上表示为,顺序在一个轮回体内挪用了进口一个位于别的的物理地址的函数。这个函数可能与以后指令的物理地位相距甚远,可是挪用的工夫差不大。在数据上表示为,顺序运用的内存是有限的(相当于任务集的巨细)。可是实践上因为RAM的随机拜访特征,顺序运用的物理内存并非延续的。恰是因为空间部分性和工夫部分性的存在,我们才提炼出今日的CPU缓存观点。
其它翻译版本 (1)
加载中
我们先用一个容易的盘算来展现一下高速缓存的效力。假定,拜访主存需求200个周期,而拜访高速缓存需求15个周期。假如运用100个数据元素100次,那末在没有高速缓存的状况下,需求2000000个周期,而在有高速缓存、并且一切数据都已被缓存的状况下,只需求168500个周期。浪费了91.5%的工夫。
用作高速缓存的SRAM容量比主存小很多。以我的经历来讲,高速缓存的巨细通常为主存的千分之一摆布(今朝通常为4GB主存、4MB缓存)。这一点自身并非甚么问题。只是,盘算机普通都会有比较大的主存,因而任务集的巨细老是会大于缓存。特殊是那些运转多过程的系统,它的任务集巨细是一切过程加入内核的总和。
处置高速缓存巨细的限制需求制订一套很好的战略来决议在给定的工夫内甚么数据应当被缓存。因为不是一切数据的任务集都是在完整类似的工夫段内被运用的,我们可以用一些技术手腕将需求用到的数据暂时交换那些以后并未运用的缓存数据。这类预取将会减少部分拜访主存的本钱,由于它与顺序的履行是异步的。一切的这些技术将会使高速缓存在运用的时分看起来比实践更大。我们将在3.3节会商这些问题。
我们将在第6章会商怎么让这些技术能很好地协助顺序员,让处置器更高效地任务。
3.1 高速缓存的地位
在深化引见高速缓存的技术细节之前,有需要阐明一下它在当代盘算机系统中所处的地位。
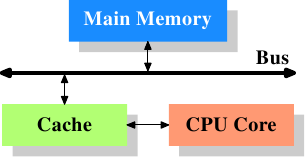
图3.1: 最容易的高速缓存设置装备摆设图
图3.1展现了最容易的高速缓存设置装备摆设。早期的一些系统就是相似的架构。在这类架构中,CPU中心不再直连到主存。{在一些更早的系统中,高速缓存像CPU与主存一样连到系统总线上。那种做法更像是一种hack,而不是真实的处理计划。}数据的读取和存储都颠末高速缓存。CPU中心与高速缓存之间是一条特别的疾速通道。在简化的表现法中,主存与高速缓存都连到系统总线上,这条总线同时还用于与其它组件通讯。我们管这条总线叫“FSB”——就是如今称谓它的术语,拜见第2.2节。在这一节里,我们将疏忽北桥。
在过来的几十年,经历标明运用了冯诺伊曼构造的
盘算机,将用于代码和数据的高速缓存离开是存在宏大优势的。自1993年以来,Intel
而且不断保持运用自力的代码和数据高速缓存。因为所需的代码和数据的内存区域是简直互相自力的,这就是为何自力缓存任务得更完满的缘由。最近几年来,自力缓存的另外一个优势渐渐浮现出来:常用处置器解码
指令的步调
是迟缓的,特别当管线为空的时分,常常会随同着错误的猜测或没法猜测的分支的呈现,
将高速缓存技术用于
指令
解码可以放慢其履行速度。
在高速缓存呈现后不久,细叱变得愈加庞杂。高速缓存与主存之间的速度差别进一步拉大,直到参加了另外一级缓存。新参加的这一级缓存比第一级缓存更大,可是更慢。因为加大一级缓存的做法从经济上思索是行欠亨的,所以有了二级缓存,乃至如今的有点系统具有三级缓存,如图3.2所示。跟着单个CPU中核数的增加,将来乃至可能会呈现更多层级的缓存。
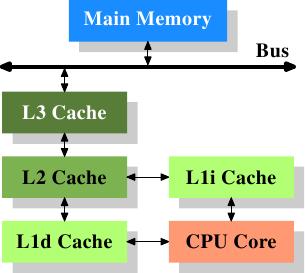
图3.2: 三级缓存的处置器
图3.2展现了三级缓存,并引见了本文将运用的一些术语。L1d是一级数据缓存,L1i是一级指令缓存,等等。请留意,这只是表示图,真实的数据流其实不需求流经领导缓存。CPU的设计者们在设计高速缓存的接口时具有很大的自在。而顺序员是看不到这些设计选项的。
本文中的一切译文仅用于进修和交换目标,转载请务必注明文章译者、出处、和本文链接。
2KB翻译任务按照
CC 协议,假如我们的任务有进犯到您的权益,请实时联络我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务



















