计算机基础
英文原文:
Memory part 3: Virtual Memory
[编辑注:本文是Ulrich Drepper的“每个程序员应该了解的内存方面的知识”文章的第三部分;这一部分谈论了虚拟内存,特别是TLB性能。没有阅读第1部分和第2部分的人可能现在就想读一读了。和往常一样,请将排字错误报告之类发送到lwn@lwn.net,而不要发送到这里的评论。]
4 虚拟内存
处理器的虚拟内存子系统为每个进程实现了虚拟地址空间。这让每个进程认为它在系统中是独立的。虚拟内存的优点列表别的地方描述的非常详细,所以这里就不重复了。本节集中在虚拟内存的实际的实现细节,和相关的成本。
虚拟地址空间是由CPU的内存管理单元(MMU)实现的。OS必须填充页表数据结构,但大多数CPU自己做了剩下的工作。这事实上是一个相当复杂的机制;最好的理解它的方法是引入数据结构来描述虚拟地址空间。
由MMU进行地址翻译的输入地址是虚拟地址。通常对它的值很少有限制 — 假设还有一点的话。 虚拟地址在32位系统中是32位的数值,在64位系统中是64位的数值。在一些系统,例如x86和x86-64,使用的地址实际上包含了另一个层次的间接寻址:这些结构使用分段,这些分段只是简单的给每个逻辑地址加上位移。我们可以忽略这一部分的地址产生,它不重要,不是程序员非常关心的内存处理性能方面的东西。{x86的分段限制是与性能相关的,但那是另一回事了}
4.1 最简单的地址转换
有趣的地方在于由虚拟地址到物理地址的转换。MMU可以在逐页的基础上重新映射地址。就像地址缓存排列的时候,虚拟地址被分割为不同的部分。这些部分被用来做多个表的索引,而这些表是被用来创建最终物理地址用的。最简单的模型是只有一级表。
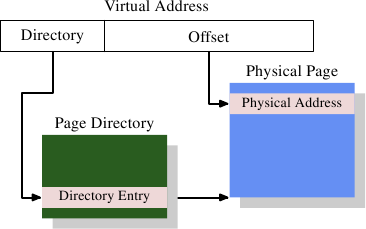
Figure 4.1: 1-Level Address Translation
图 4.1 显示了虚拟地址的不同部分是如何使用的。高字节部分是用来选择一个页目录的条目;那个目录中的每个地址可以被OS分别设置。页目录条目决定了物理内存页的地址;页面中可以有不止一个条目指向同样的物理地址。完整的内存物理地址是由页目录获得的页地址和虚拟地址低字节部分合并起来决定的。页目录条目还包含一些附加的页面信息,如访问权限。
页目录的数据结构存储在内存中。OS必须分配连续的物理内存,并将这个地址范围的基地址存入一个特殊的寄存器。然后虚拟地址的适当的位被用来作为页目录的索引,这个页目录事实上是目录条目的列表。
作为一个具体的例子,这是 x86机器4MB分页设计。虚拟地址的位移部分是22位大小,足以定位一个4M页内的每一个字节。虚拟地址中剩下的10位指定页目录中1024个条目的一个。每个条目包括一个10位的4M页内的基地址,它与位移结合起来形成了一个完整的32位地址。
4.2 多级页表
4MB的页不是规范,它们会浪费很多内存,因为OS需要执行的许多操作需要内存页的队列。对于4kB的页(32位机器的规范,甚至通常是64位机器的规范),虚拟地址的位移部分只有12位大小。这留下了20位作为页目录的指针。具有220个条目的表是不实际的。即使每个条目只要4比特,这个表也要4MB大小。由于每个进程可能具有其唯一的页目录,因为这些页目录许多系统中物理内存被绑定起来。
解决办法是用多级页表。然后这些就能表示一个稀疏的大的页目录,目录中一些实际不用的区域不需要分配内存。因此这种表示更紧凑,使它可能为内存中的很多进程使用页表而并不太影响性能。.
今天最复杂的页表结构由四级构成。图4.2显示了这样一个实现的原理图。

Figure 4.2: 4-Level Address Translation
在这个例子中,虚拟地址被至少分为五个部分。其中四个部分是不同的目录的索引。被引用的第4级目录使用CPU中一个特殊目的的寄存器。第4级到第2级目录的内容是对次低一级目录的引用。如果一个目录条目标识为空,显然就是不需要指向任何低一级的目录。这样页表树就能稀疏和紧凑。正如图4.1,第1级目录的条目是一部分物理地址,加上像访问权限的辅助数据。
为了决定相对于虚拟地址的物理地址,处理器先决定最高级目录的地址。这个地址一般保存在一个寄存器。然后CPU取出虚拟地址中相对于这个目录的索引部分,并用那个索引选择合适的条目。这个条目是下一级目录的地址,它由虚拟地址的下一部分索引。处理器继续直到它到达第1级目录,那里那个目录条目的值就是物理地址的高字节部分。物理地址在加上虚拟地址中的页面位移之后就完整了。这个过程称为页面树遍历。一些处理器(像x86和x86-64)在硬件中执行这个操作,其他的需要OS的协助。
系统中运行的每个进程可能需要自己的页表树。有部分共享树的可能,但是这相当例外。因此如果页表树需要的内存尽可能小的话将对性能与可扩展性有利。理想的情况是将使用的内存紧靠着放在虚拟地址空间;但实际使用的物理地址不影响。一个小程序可能只需要第2,3,4级的一个目录和少许第1级目录就能应付过去。在一个采用4kB页面和每个目录512条目的x86-64机器上,这允许用4级目录对2MB定位(每一级一个)。1GB连续的内存可以被第2到第4级的一个目录和第1级的512个目录定位。
但是,假设所有内存可以被连续分配是太简单了。由于复杂的原因,大多数情况下,一个进程的栈与堆的区域是被分配在地址空间中非常相反的两端。这样使得任一个区域可以根据需要尽可能的增长。这意味着最有可能需要两个第2级目录和相应的更多的低一级的目录。
其它翻译版本 (1)
加载中
但即使这也不常常匹配现在的实际。由于安全的原因,一个可运行的(代码,数据,堆,栈,动态共享对象,aka共享库)不同的部分被映射到随机的地址[未选中的]。随机化延伸到不同部分的相对位置;那意味着一个进程使用的不同的内存范围,遍布于虚拟地址空间。通过对随机的地址位数采用一些限定,范围可以被限制,但在大多数情况下,这当然不会让一个进程只用一到两个第2和第3级目录运行。
如果性能真的远比安全重要,随机化可以被关闭。OS然后通常是在虚拟内存中至少连续的装载所有的动态共享对象(DSO)。
4.3 优化页表访问
页表的所有数据结构都保存在主存中;在那里OS建造和更新这些表。当一个进程创建或者一个页表变化,CPU将被通知。页表被用来解决每个虚拟地址到物理地址的转换,用上面描述的页表遍历方式。更多有关于此:至少每一级有一个目录被用于处理虚拟地址的过程。这需要至多四次内存访问(对一个运行中的进程的单次访问来说),这很慢。有可能像普通数据一样处理这些目录表条目,并将他们缓存在L1d,L2等等,但这仍然非常慢。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接。
2KB翻译工作遵照
CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。

2KB项目(www.2kb.com,源码交易平台),提供担保交易、源码交易、虚拟商品、在家创业、在线创业、任务交易、网站设计、软件设计、网络兼职、站长交易、域名交易、链接买卖、网站交易、广告买卖、站长培训、建站美工等服务



















